Chapter 6
The Decision Tree — Structure and Syntax
Last updated: 2026-04-10 Open for review
“A law is not a law unless it is understood.” Jeremy Bentham, Of Laws in General, c. 1782 (published posthumously 1945)
From Text to Executable Logic: The Dual Publication Model
At the core of any proposal for the automation of legal reasoning is the question about what exactly is the relationship between a statute and the software that applies it? Is the software a faithful implementation of the statute, or an interpretation of it? If it is an implementation, who verified it? If it is an interpretation, whose interpretation is it, and by what authority does it bind? And in either case: how would anyone know?
These questions have been present, unanswered, in every digital governance system ever built.1 They have been unanswered not because they are unanswerable, but because no institutional mechanism has existed to answer them. Legislatures publish statutes. They do not publish algorithms. And in the absence of an authoritative bridge between the two (a formally specified, publicly available, democratically accountable account of how the statute translates into applicable logic) the bridge has been built privately, by software developers, without oversight, and without any mechanism for verification by the institutions whose authority the software purports to exercise2.
The OLRF’s dual publication model is proposed as the institutional mechanism that has been missing. Its premise is simple: every piece of legislation that is to be applied by automated systems should be published in two forms simultaneously. The traditional human-readable statutory text, and a machine-applicable representation of the legal logic that text embodies. These two forms are not alternatives. They are complements. The statutory text remains the primary legal source: the authoritative statement of the legislature’s will, interpretable by courts, contestable by citizens, and amendable through the democratic process. The machine-applicable representation (the Decision Tree) is a derived artefact: an authoritative account of how the norm is to be applied, published alongside the text, linked to it at sub-paragraph level, and versioned in synchrony with it.
The model accommodates two distinct modes of publication. In interpretive mode3, the Decision Tree is published by the competent administrative authority as an authoritative statement of how that authority understands and intends to apply the norm. It does not bind the courts, which remain fully free to assess whether the interpretation is legally correct. It does, however, bind the authority’s own systems: every automated application must follow the publicly declared interpretation, rather than one embedded silently in internal software. In authoritative mode4, the Decision Tree is published by the legislature itself, or by a body acting under delegated authority, as a binding component of the legal instrument. In that case, the Decision Tree is not merely a guide to application. It forms part of the law. A system that deviates from it has not committed a technical defect. It has misapplied the norm, with the same legal consequences as any other departure from enacted law: the resulting determination is challengeable, reviewable, and potentially voidable on grounds of illegality.
Both modes mark a significant advance over the current situation, in which the executable form of law typically has no formal status at all. Which mode is appropriate is not a technical matter but a constitutional and policy choice. The OLRF architecture supports both without prescribing one universal solution. What it requires is that the choice be made consciously, recorded formally, and reflected in the architecture itself.
In Model A, the tree is the deterministic evaluator. In Model B, the tree is the normative framework for validation. In Model C, the tree is the audit protocol. In all three models, the tree is derived from the text, linked to it through sub-normative anchors, published in the Registry, and available for public inspection. What changes is the operational relationship between tree and determination. What is constant is the requirement that the normative basis be publicly specified, verifiable, and democratically accountable.
Anatomy of a Decision Tree
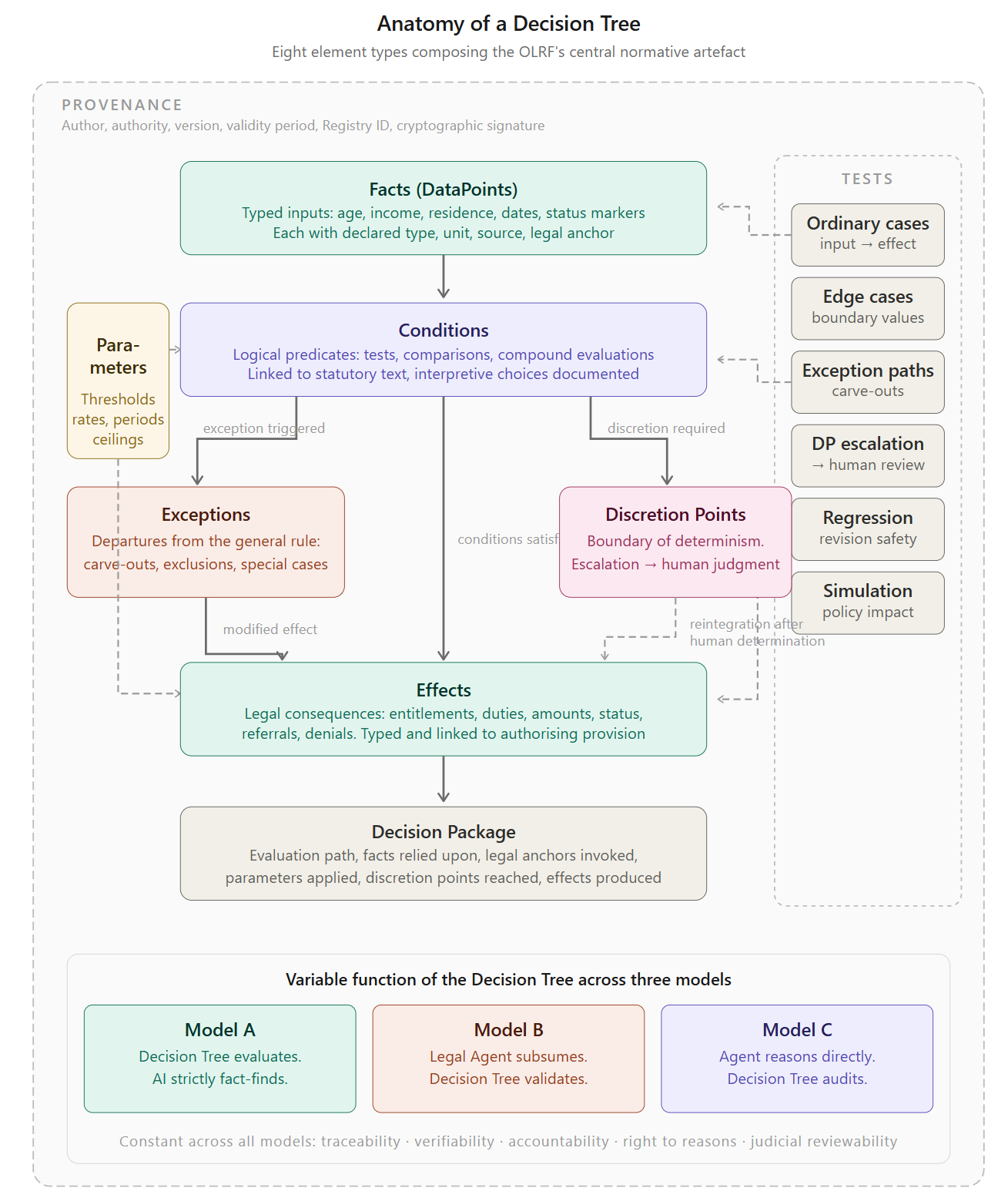
The Decision Tree is the central artefact of the OLRF. It is not merely a flowchart, even if it can be rendered visually as one. Nor is it simply a program, even if it can be executed by a conformant engine. It is a formal representation of legal logic in applicable form: a structured, typed, versioned, and cryptographically signed specification of the facts a norm depends on, the conditions it evaluates, the legal consequences it produces, and the limits within which it can be applied.5
To perform this function, the Decision Tree brings together seven distinct element types6. Each captures a different aspect of legal reasoning. Each is necessary if the executable form of a norm is to remain intelligible to drafters, reviewable by lawyers and courts, and reliable for the systems that implement it7.
1. Facts (DataPoints)
Facts are the inputs on which the Decision Tree operates. They represent the empirical elements to which the law attaches significance: age, income, residence, dates, status markers, classifications, and other legally relevant circumstances. Every Fact has a declared type (Boolean, integer, decimal, string, date, enum, or reference to a controlled code list). Where relevant, it also carries a unit of measurement, a declared source indicating where the value is expected to come from (a civil register, a tax record, a self-declaration), a confidence threshold specifying the minimum reliability required, and a legal anchor linking it to the provision that makes the fact relevant in the first place.
Facts are not informal assumptions and not approximations inferred at runtime without discipline. They are validated data elements, defined in advance, checked against schema constraints before evaluation, and recorded in the Decision Package together with both their value and their provenance. In Model A, the DataPoint schema is the contract between the fact-finding AI agent and the deterministic evaluation engine: facts that do not conform are rejected before they reach the evaluator. In Models B and C, the schema defines the validation or audit criteria for the agent’s factual record.
The DataPoint schema plays a critical role in addressing the fact framing problem8 identified in Chapter 4: The Controlled Division of Labour Between Humans and AI. It requires the agent to document not only the value of each fact but also the interpretive choice that produced it, the source consulted, the alternative readings considered, and the confidence level assigned9.
2. Conditions
Conditions are the logical predicates through which the norm is applied to facts. They express the tests by which the system determines whether a rule applies, how it applies, and what path the evaluation should take. Some conditions are simple comparisons (income below threshold). Others combine multiple factual and normative elements into compound tests (resident and employed and not receiving benefit X). Still others reflect more deeply nested structures in which multiple branches of a provision interact (qualifying under subsection (a) unless excluded by subsection (c) as modified by paragraph 3)10.
Each condition carries a legal anchor identifying the specific legislative text from which the test derives. A condition without a legal anchor is a programming decision. A condition with a legal anchor is a normative claim, verifiable against the statute and challengeable in court11.
Conditions may also carry metadata specifying the type of legal reasoning they embody. A condition that tests whether a numerical value exceeds a defined threshold is a bound determination (gebundene Entscheidung). A condition that tests whether a set of circumstances constitutes “special hardship” (besondere Härte) is an indeterminate legal concept (unbestimmter Rechtsbegriff). A condition that asks whether a measure is “proportionate” is a proportionality assessment12. This metadata is not required for the execution of the tree (the engine does not need to know which type of legal reasoning a condition represents). It is required for the constitutional classification of the tree’s elements and for the validation and audit functions in Models B and C.
3. Effects
Effects are the legal consequences that the evaluation produces when the applicable conditions are satisfied. They are the determinations that matter: the grant of a benefit, the assessment of a tax, the issuance of a permit, the imposition of an obligation, the referral to another proceeding. Effects are formally typed (grant, deny, calculate, refer, escalate, notify) and carry the legal anchor that traces them to the specific statutory provision authorising the consequence.
An Effect may be unconditional (the consequence follows directly from the satisfaction of the conditions) or conditional on the resolution of a Discretion Point (the consequence is provisional until a human official exercises judgment on a related element). In the latter case, the Effect carries a dependency reference to the Discretion Point that must be resolved before the Effect can be finalised.
4. Exceptions
Exceptions are the elements that limit, override, or modify the application of a general rule under specified circumstances. In legislation, exceptions are among the most legally significant and most error-prone elements13. A rule that appears straightforward may be subject to three exceptions, one of which is itself subject to a counter-exception, creating a hierarchy of specificity that must be traversed correctly for the determination to be lawful.
The Decision Tree models exceptions explicitly, with each exception linked to the specific clause or sub-clause of the provision that establishes it, and to the general rule from which it derogates. This bidirectional structure (exception linked to its textual source and to the rule it overrides) makes the relationship between general norm and derogation formally visible14. The execution semantics define a strict priority ordering among exceptions: more specific exceptions override more general ones, later-enacted exceptions override earlier ones (where the statute specifies this), and the priority of competing exceptions is documented in the tree’s metadata15.
The Catala programming language, developed at Inria by Merigoux, Chataing, and Protzenko, has demonstrated that default logic (the formal framework for reasoning with exceptions and overrides) can be embedded as a first-class language feature16. The OLRF’s treatment of exceptions draws on this insight, though it does not adopt Catala’s specific syntax, for reasons discussed in the section on language choice below.
5. Parameters
Parameters are the externally set values on which the Decision Tree operates but which the tree itself does not determine: thresholds, rates, qualifying periods, income limits, fee schedules. Many legal provisions establish a framework of conditions and consequences while delegating to an administrative body the authority to set the specific values that the framework operates on. The Decision Tree’s Parameters embody those values.
Each Parameter carries a delegated_by anchor linking it to the provision that confers the delegation, a validity period specifying when the value is in force, and (where applicable) a reference to the administrative act that established the current value17. Parameters are versioned independently of the tree’s logic: when the income threshold for a benefit changes, the Parameter is updated, not the tree’s condition structure. This separation between logic and values mirrors the legal distinction between the norm (which the legislature enacts) and the values that administrative bodies set within the norm’s framework.
6. Discretion Points
Discretion Points are the nodes at which the Decision Tree’s deterministic evaluation reaches its constitutionally mandated limit and must be escalated to a human decision-maker. They are the architectural embodiment of the principle that certain decisions must remain with human officials, not because the machine cannot produce an output, but because the constitution requires that a human being exercise judgment18.
Discretion Points are described in detail in a later chapter. For the purposes of the tree’s anatomy, it is sufficient to note that each Discretion Point carries: a classification (Type A: unassisted, Type B: AI-assisted, Type C: escalated), the legal anchor identifying the provision that confers the discretionary authority, the DataPoint dependencies that define which facts the official will need, and (for Type B) the specification of the AI-Assistance-Package that will be generated to support the official’s judgment19.
7. Provenance Metadata
Every Decision Tree carries metadata identifying who constructed it, under whose authority, when it was published, in which publication mode (interpretive or authoritative), and by which cryptographic signature its integrity is secured. This metadata is not administrative ornament. It is what allows the Decision Tree to function as a public and reviewable legal artefact rather than a private implementation hidden inside software. Provenance establishes the chain of responsibility through which the tree can be trusted, challenged, and institutionally located.
8. Test Suites as a Basis for Certification
Tests are the formal verification layer that accompanies the Decision Tree. They consist of structured test cases linking specified input facts to expected legal effects. Every test case is a concrete assertion: given these facts, this Decision Tree must produce this outcome. The test suite is published alongside the Decision Tree in the Registry and is subject to the same version control and cryptographic signing as the tree itself.
The test suite is organised into six categories, each addressing a different dimension of the tree’s normative behaviour.
Ordinary cases test the tree’s response to the standard fact patterns that the norm is designed to address. They verify that the tree produces the correct legal effect for the common case: the applicant who clearly qualifies, the taxpayer whose liability is straightforward, the licence application that meets all conditions. These tests establish baseline correctness. An implementation that fails ordinary cases is fundamentally defective.
Edge cases test the tree’s behaviour at the boundaries of its conditions: income exactly at the threshold, age precisely at the qualifying date, a period that falls one day short of the minimum. These are the points at which implementation errors most commonly arise, because boundary behaviour depends on precise specification of comparison operators (greater than versus greater than or equal to), rounding rules, and temporal calculation methods. Edge case tests verify that the tree handles boundaries as the statute intends, not as a programmer assumes.
Exception paths test the tree’s treatment of the explicitly modelled exceptions. Every Exception element in the tree (Chapter 6, Anatomy) must have at least one test case that triggers it and at least one that does not, so that both the activation and the non-activation of the exception are verified. Exception paths are where legal complexity is most concentrated and where the Coverage Map’s “Contested” classification is most likely to apply. Testing them systematically is therefore not merely a technical precaution. It is a legal quality assurance measure.
Discretion Point escalation tests verify that the tree correctly identifies the points at which deterministic evaluation must stop and human judgment must begin. For every Discretion Point in the tree, the test suite includes at least one scenario that triggers the escalation and verifies that the system produces a structured escalation record (including the full evaluative context, the criteria for the exercise of discretion, and the documentation requirements) rather than a deterministic output. These tests verify not that the system can decide, but that it knows when it must not decide.
Regression tests protect the tree against unintended side effects of revisions. When a Parameter is updated, an Exception is refined, or a Condition is reformulated, regression tests verify that the change affects only what it is intended to affect. They consist of the complete test suite from the previous version, re-executed against the revised tree. Any difference in outcome between the old and the new version that is not explained by the documented change constitutes a regression and must be investigated before the revised tree enters into force.
Simulation tests enable a form of legislative impact assessment that narrative regulation cannot support. By running the test suite across a population of synthetic or anonymised real cases, policymakers can observe the likely practical effects of proposed changes before the norm is enacted. How many cases would be affected by a change in the income threshold? Which population segments would gain or lose eligibility under a revised exception? What would be the fiscal impact of adjusting a Parameter value? These questions, which in the narrative world require months of expert estimation, become answerable in hours when the norm exists as a testable specification. Simulation tests do not replace political judgment about whether a change is desirable. They inform that judgment with evidence that was previously unavailable20.
The test suite serves a dual function that extends beyond the verification of the Decision Tree itself. It is also the baseline for agent certification (Chapter 10). An agent that seeks certification to operate on a Decision Tree under Model B or C must demonstrate that it can correctly process the tree’s complete test suite: the ordinary cases, the edge cases, the exception paths, and the escalation scenarios. An agent that fails the test suite for a given Decision Tree cannot be certified for the normative domain that tree implements. The certification test suite (Chapter 10) adds further categories beyond the Decision Tree’s own tests: adversarial inputs, consistency across case populations, reasoning chain quality (Model C), and discrimination testing. But the Decision Tree’s test suite is the foundation on which all further certification testing rests. In this sense, every test suite is both a verification instrument for the tree and an entry examination for the agents that seek to operate on it21.
For all of these reasons, Tests are not a technical appendage to the Decision Tree. They are an integral part of the normative artefact. A Decision Tree published without a test suite is an assertion without evidence. A Decision Tree published with a comprehensive test suite is a verifiable commitment: the responsible authority has declared not only how the norm is to be applied, but has demonstrated, through concrete cases, that the specification produces the outcomes the law requires, answering the evaluation challenge that the AI and Law research community has, for decades, failed to address22.
The Question of Language and Syntax
The preceding sections describe what a Decision Tree contains. This section addresses a question that is technically consequential and politically contentious: in what language should a Decision Tree be written?
The question is not merely one of engineering preference. The choice of language determines who can read the tree, who can write it, who can verify it, and therefore who holds effective power over the normative specification that governs automated decisions about people’s lives. A language that only programmers can read concentrates that power in the hands of development teams. A language that lawyers can also read distributes it more broadly. A language that citizens can inspect (even if they require assistance to understand it fully) is the most democratic option, though also the most technically challenging.
The field of Law as Code has produced several approaches to this problem, each embodying different assumptions about what “making law executable” requires.
Blawx (Canada School of Public Service, 2022 ff.)
Blawx is an open source web-based tool developed by the Canada School of Public Service for encoding, testing, and using legal rules. Its distinctive contribution to the landscape is that it addresses the user-developer gap identified in Canada’s Rules as Code experiments: the observation that the most appropriate formal language for legal knowledge representation (declarative logic) is also the least accessible to the legal professionals who possess the domain expertise. Blawx solves this through a visual programming interface based on Google’s Blockly library, which represents logical predicates, rules, and exceptions as interlocking blocks that can be assembled without writing text-based code. The underlying reasoning engine is s(CASP), a constraint answer set programming system running on SWI-Prolog. This combination gives Blawx defeasibility (rules can override other rules, modelling the exception structure of legislation without restructuring the encoding) and open-world reasoning (the absence of evidence is not treated as evidence of absence, reflecting the legal distinction between “not proven” and “false”). Blawx also provides automated explanations for its conclusions, linked back to the relevant sections of the source law, and supports hypothetical reasoning. Canada has used Blawx in regulatory drafting experiments with the Treasury Board Secretariat, encoding a “Definition of Salary” regulation under the Public Service Superannuation Act. For the OLRF, Blawx represents a different point in the design space than Catala: where Catala produces a compiled specification whose correctness can be formally verified, Blawx produces a knowledge base whose conclusions can be queried, explained, and tested against scenarios. Its orientation toward non-programmer users and its declarative logic foundation make it a natural candidate for encoding the sub-normative reasoning structures that the OLRF locates at the Discretion Point interface (Chapter 9), where legal professionals rather than software engineers must be able to inspect and validate the encoded logic23.
Catala
Developed at Inria by Merigoux, Chataing, and Protzenko, Catala is a very ambitious attempt to create a true domain-specific language for legislative implementation.24 Catala is based on default logic (formalised by Sarah Lawsky for statutory reasoning) and uses a literate programming approach: the legislative text and the executable code are interleaved, so that each line of code annotates the specific passage of law it implements. The Catala compiler’s correctness has been proven using the F* proof assistant. In testing against French family benefits and US federal income tax (Section 121), Catala uncovered a bug in the official French government implementation. The French government has adopted Catala for the rewriting of its income tax computation system.
Catala’s strength is its alignment with legal reasoning: the general-rule-with-exceptions structure of legislation maps directly onto Catala’s default logic semantics. Its limitation is adoption scope. Catala is designed for norms that are “algorithms in disguise” (its creators’ phrase)[^63]: provisions that leave little room for interpretation and essentially describe a computation or a decision procedure. This covers tax calculations, benefit eligibility determinations, and fee assessments. It covers Model A of this paper’s framework. It does not naturally extend to Model B (where the agent’s reasoning about open texture must be validated) or to Model C (where the tree serves as an audit protocol for autonomous legal reasoning).
DMN (Decision Model and Notation)
Standardised by the OMG in 2014, represents decisions in tabular form25. Decision tables are readable by non-programmers and integrate well with business process management systems. DMN’s strength is its simplicity: a decision table can be understood by a policy officer with no programming training. Its limitation is expressive power. Complex exception hierarchies, temporal dependencies, cross-referential definitions, and proportionality structures are difficult to represent in tabular form without losing the legal structure that makes them meaningful. DMN is well suited to flat, condition-consequence rules. It struggles with the recursive, exception-laden, cross-referential structures that characterise modern legislation.
eFLINT
Developed at the University of Amsterdam by van Binsbergen, Liu, van Doesburg, and van Engers, eFlint takes a distinctive approach grounded in Hohfeld’s framework of fundamental legal conceptions (rights, duties, powers, immunities) and transition systems.26 Where Catala focuses on the computational structure of statutory provisions (conditions, consequences, exceptions), eFLINT focuses on the normative relationships between actors: who is permitted to perform which action, who has a duty toward whom, and how these normative positions change as events occur. The resulting specifications are executable and support automatic case assessment, scenario exploration, and compliance monitoring. eFLINT has been evaluated against the GDPR (Articles 6(1)(a) and 16) and has been applied in the Netherlands to model-driven case management for administrative law proceedings. Its strength is its explicit modelling of normative dynamics: the creation, termination, and modification of duties and powers as a case unfolds over time. Its limitation for the OLRF context is complementary to Catala’s: eFLINT excels at modelling the normative relationships between actors in a process but is less focused on the computational derivation of a specific legal outcome from a set of facts, which is the Decision Tree’s primary function. eFLINT’s approach to normative actor modelling is, however, directly relevant to the OLRF’s Agent Layer, where the question of which agent is permitted to perform which action under which conditions is precisely the governance problem that eFLINT seems to be designed for to properly address.
L4
Developed by Legalese in Singapore, approaches the problem from contract law rather than administrative law.27 It models legal agreements as collections of obligations, permissions, and powers, drawing on Hohfeldian legal theory. L4’s relevance to the OLRF proposal is limited (administrative law and contract law have different structural requirements), but its exploration of embedded DSL design (a domain-specific language hosted within a general-purpose language) is instructive.
LegalRuleML
An OASIS standard extending RuleML, was one of the first attempts to encode the subtleties of legislation in a machine-processable format.28 It handles obligations, permissions, exceptions, and temporal aspects through an XML markup vocabulary. LegalRuleML’s strength is its semantic richness: it can express deontic modalities (obligation, permission, prohibition) that other formats cannot. Its limitation is usability. LegalRuleML documents are XML structures that require significant expertise to write and to read. The gap between the legislative text and its LegalRuleML representation is large, which makes verification by legal professionals difficult or impossible without specialised tooling.
OpenFisca
developed in France since 2011 and recognised by the OECD as a principal implementation of the Rules as Code movement, takes a different approach.29 It embeds its DSL within Python, the most widely used data science language. Legislative rules are expressed as Python classes with a domain-specific vocabulary for variables, parameters, and formulas. OpenFisca’s strength is its ecosystem: it powers real government services in France (tax simulation, benefit eligibility, legislative impact assessment), New Zealand, Australia, and several other countries. Its limitation is that its Python embedding makes the normative specification inseparable from the implementation language. A lawyer reviewing an OpenFisca formula must understand Python syntax. The normative content is entangled with programming constructs.
PolicyEngine (PolicyEngine, Inc., 2021 ff.)
PolicyEngine is a nonprofit that builds open source microsimulation models of national tax and benefit systems, currently covering the United States (federal and all 50 states) and the United Kingdom. It is architecturally a fork of OpenFisca Core (renamed PolicyEngine Core) and therefore inherits OpenFisca’s Python-embedded rule definition approach. Its significance for the landscape is not technical novelty but operational scale and institutional adoption. PolicyEngine US encodes the complete US federal and state tax-benefit system as a rules engine with parameterised variables, temporal versioning, and vectorised calculation. The PolicyEngine web application allows users to design custom tax-benefit reforms and simulate their population-level effects. PolicyEngine’s co-founder served as an Innovation Fellow at 10 Downing Street, adapting the system for UK government policy analysis. The organisation maintains a partnership with the National Bureau of Economic Research (NBER) for building an open source TAXSIM emulator. For the OLRF, PolicyEngine demonstrates both the potential and the limitation of the OpenFisca lineage at scale. The potential: it is the clearest existing proof that a parameterised, Python-embedded rules engine can encode an entire national tax-benefit system with sufficient fidelity for government use. The limitation: the normative content remains entangled with the implementation language, provenance traceability to statutory text is maintained by documentation rather than formal metadata, and the system’s value depends on a community of maintainers who understand both the law and the code. PolicyEngine does not solve the separation problem that the OLRF considers constitutionally essential. But it demonstrates that the operational problem of encoding law at national scale is tractable, which is a prerequisite for any architecture that claims to operate at that scale.30
RegelRecht (Netherlands Ministry of the Interior, 2024 ff.)
RegelRecht is a proof of concept by the Dutch Ministry of the Interior (Bureau Architectuur Digitale Overheid, MinBZK) for the execution of machine-readable specifications of Dutch legislation. The project builds on regels.overheid.nl, the Dutch government’s rule documentation and publication platform, and extends it in a direction directly relevant to the OLRF: from documentation to execution. Rule specifications in RegelRecht are not just descriptions of law. They are executable code, accompanied by an engine that can run, validate, and test them. The project uses a YAML-based specification format, with each law modeled as a self-contained specification file that includes conditions, calculations, parameters, and references to the authoritative statutory source (via wetten.overheid.nl identifiers). Implemented laws include the AOW (pension calculation), Zorgtoeslag (healthcare benefit), Huurtoeslag (housing benefit), Participatiewet (social assistance), the Kieswet (electoral law), and administrative law procedures under the Algemene wet bestuursrecht. A Go-based execution engine and a Python engine run the specifications. The project also provides an MCP server that exposes three tools: execute_law, check_eligibility, and calculate_benefit_amount, making law specifications directly accessible to AI agents. RegelRecht is open source under the EUPL. For the OLRF, RegelRecht is significant in three respects. First, its specifications are structurally close to what the OLRF calls Decision Trees: deterministic, traceable to legislative source, parameterised, and temporally addressable. Second, its explicit separation of rule specification from execution engine mirrors the OLRF’s principle that the normative basis and the evaluation mechanism must remain distinct. Third, its MCP integration anticipates the interface layer described in Chapter 8. The limitation is similar as with OpenFisca: the specification language is not a purpose-built legal DSL. It is structured data (YAML) interpreted by an execution engine, not a language that encodes the semantic structure of legal reasoning. The relationship between the specification and the statutory text is maintained by convention and documentation, not by formal provenance metadata31.
Rulemapping
developed by S. Breidenbach and the Rulemapping Group with support from SPRIND, takes a deliberately visual and no-code approach.32 Laws and administrative procedures are translated into structured, visual decision trees (Rulemaps) that are simultaneously human-readable and machine-executable. The method relies on configuration rather than programming: legal experts model norms directly in the Rulemap Builder without requiring software development skills, producing logic models that can be deployed through the Rulemapping Automation Platform for form validation, case decisions, and workflow management. The German Federal Ministry of Justice already uses Rulemapping in legislative projects, and the German Nationaler Normenkontrollrat has identified the method as a potential solution for the digital drafting of new legislation. A distinctive feature of the Rulemapping platform is its combination of deterministic rule models with probabilistic language models (Rule AI): unstructured data is processed by the LLM, while the legal determination follows the published Rulemap, with every automated decision documented, auditable, and traceable to the specific legal rule it implements. This architecture mirrors, at the product level, the separation principle proposed in this paper. Rulemapping’s strength is its accessibility: the visual, no-code approach lowers the barrier for legal professionals to participate directly in the creation of executable normative specifications, without mediation by programmers. Its focus on visual decision trees makes it a natural candidate for authoring OLRF Decision Trees in the interpretive publication mode, particularly for jurisdictions that prioritise broad participation of legal professionals in the authoring process.
The OLRF Draft Position: Format Neutrality with Structural Requirements
The OLRF does not propose a new DSL. Nor does it mandate the use of any specific existing language. Instead, it defines a set of structural requirements that any conformant representation must satisfy, and it specifies a canonical serialisation format (JSON-based, with a formal JSON Schema) that serves as the interchange format between all components of the architecture.
This is a deliberate design choice, and it requires justification, because the case for a dedicated legal DSL is strong.
The argument for a dedicated DSL is that it would ensure readability by legal professionals, enforce correct handling of exceptions and defaults, prevent the entanglement of normative content with implementation logic, and provide a single shared medium through which lawyers and programmers can collaborate. Catala has demonstrated that all of these goals are achievable.
The argument against mandating a specific DSL for the OLRF is institutional, not technical. The OLRF is proposed as an international framework, submitted for consultation through the OECD, intended for adoption across jurisdictions with different legal traditions, different technical infrastructures, and different institutional capacities. Mandating a specific DSL would create a dependency on a single language project (however excellent), would require every participating jurisdiction to adopt that language, and would make the framework’s viability contingent on the language’s continued development and governance.
The OLRF proposes instead to specify what a Decision Tree must contain (the seven element types described above), how its elements must be linked to legislative text (the sub-normative anchor system), what execution semantics it must satisfy (deterministic evaluation, described below), and what interchange format it must be serialisable into (the canonical JSON representation). Any language that can produce a conformant serialisation is a valid authoring language. A jurisdiction that chooses to author its Decision Trees in Catala or in Rulemapping Method can do so, provided the respective compiler produces output conformant with the OLRF schema. A jurisdiction that prefers OpenFisca, DMN, LegalRuleML, or a general-purpose language with appropriate tooling can do so on the same terms.
This approach sacrifices the elegance of a single shared medium in exchange for institutional feasibility. It accepts that different jurisdictions will author their Decision Trees differently. What it does not accept is that the resulting trees will be structurally incompatible, semantically ambiguous, or unverifiable. The structural requirements and the canonical interchange format ensure interoperability without mandating uniformity of authoring practice.
The OLRF specification does, however, make one recommendation (distinct from a requirement): jurisdictions that are starting from scratch, without an established Law as Code infrastructure, should seriously consider joining one of the above described DSL projects. The architecture would work without a DSL and there are good reasons to not apply one.
Sub-normative Linkage: The Fine Thread Between Code and Law
In the documentation of digital governance systems, a widespread practice has established itself that can be described as paragraph-level accountability: a system that applies a legal norm records, somewhere in its documentation, the paragraph or article number of the underlying provision. Section 49a of the Social Code. Article 8 of the Consumer Credit Directive. Paragraph 35a of the Administrative Procedure Act. The reference exists. The statutory basis is named.
This practice is not wrong, but it is insufficient. A single paragraph of legislation typically contains multiple normative elements: a general rule, one or more conditions for its application, a legal consequence, exceptions to the general rule, cross-references to definitions in other provisions, delegations of authority to administrative bodies, and sometimes discretionary elements. These elements are not distributed uniformly across the paragraph. They are located in specific sentences, specific clauses, specific sub-clauses, and specific numbered items. The condition that establishes eligibility may reside in the first sentence. The exception that overrides it may reside in the third sentence, second half-clause, item two. The definition on which both depend may be found in a different article of the same statute, or in a different statute entirely.
If a system links its logic to the paragraph as a whole, it documents only that something in the system relates to something in the provision. Which specific condition was operationalised, and from which specific sentence it derives, remains invisible. Which specific exception was or was not included, and from which sub-clause it originates, remains invisible. The interpretive choice that resolved an ambiguity between the general rule and an exception (a choice that may be the most legally significant decision in the entire implementation) is not merely undocumented at paragraph level. It is structurally undocumentable, because the paragraph as a unit of reference is not fine-grained enough to capture it.
Sub-normative linkage is the architectural response to this deficit. The principle requires that every element of a Decision Tree (every Condition, every Effect, every Exception, every Parameter, every Discretion Point) be linked not to a provision as a whole, but to the specific unit of legislative text from which it derives: the sentence, the clause, the sub-clause, the numbered item. The link must be precise enough that a lawyer, given the Decision Tree element and the link, can identify the exact words from which the element was derived and form an independent judgment on whether the derivation is correct.33
The Five Anchor Types
A Decision Tree element can relate to a legislative text passage in qualitatively different ways. A condition that directly implements the wording of a provision has a different relationship to that text than an exception that limits the condition’s scope, a definition that determines the meaning of the condition’s key terms, or a delegation that authorises an administrative body to set the threshold the condition tests against. These are not variations of the same relationship. They are distinct categories of normative derivation. If all of them are recorded simply as “a reference to provision X,” these distinctions collapse, and it becomes impossible to determine, from the Decision Tree alone, whether the legal reasoning it embeds is correct.
The OLRF addresses this through a typed anchor system. Every link between a Decision Tree element and a legislative text passage carries a relationship type that characterises the nature of the normative derivation. Five anchor types are defined.34
derived_from is the foundational anchor type. It expresses the direct normative derivation of a Decision Tree element from a specific textual provision. A Condition that tests whether an applicant’s income falls below a specified threshold is derived_from the sentence in the statute that establishes the income condition. An Effect that grants a specified amount is derived_from the sentence that establishes the entitlement. This is the anchor type that a court will examine first when reviewing whether a Decision Tree correctly operationalises a provision.
constrained_by expresses the relationship between a Decision Tree element and a textual provision that limits its scope of application. This is typically a cross-reference, a definitional provision, or a provision in another statute that narrows what the element can do or to whom it can apply. A Condition that tests residency is constrained_by the definitional provision that specifies what “resident” means for the purposes of the statute. An Effect that grants a benefit is constrained_by the provision in a different statute that makes the benefit subject to a means test. The constrained_by anchor makes these limiting relationships visible, and therefore verifiable, in a way that paragraph-level linking cannot.
delegated_by expresses the relationship between a Decision Tree element (typically a Parameter) and the provision that confers the authority to set that element’s value. Many legal provisions establish a framework of conditions and consequences while delegating to an administrative body the authority to set the specific values the framework operates on: the income threshold, the qualifying period, the benefit rate. The delegated_by anchor links each Parameter to the provision that authorises the publishing authority to set it. This link is constitutionally significant: it establishes that the Parameter’s value is not an arbitrary choice but an exercise of a specific delegated power. Without it, the Parameter is a number without a legal basis.
exception_from expresses the relationship between an Exception element in the Decision Tree and the specific clause or sub-clause that establishes the exception. The bidirectional structure (exception linked to its textual source and to the general rule from which it derogates) makes the relationship between general norm and derogation formally visible, enabling courts to verify that the exception was correctly identified, correctly scoped, and correctly applied.
defined_in expresses the relationship between a Decision Tree element and a definitional provision that establishes the legal meaning of a term the element uses. Such a provision may reside within the same statute or in another. Legal definitions are a pervasive feature of modern legislation and a persistent source of implementation error: a system that uses a common-language understanding of a term where the statute has provided a technical legal definition has produced an incorrect implementation, regardless of how faithfully it has reproduced the rest of the norm’s logic. The defined_in anchor makes definitional dependencies explicit and ensures that any change to a definition propagates visibly through the Decision Tree to every element that depends on it.
The five anchor types, taken together, constitute a formal grammar of normative derivation: a vocabulary for describing, with legal precision, how every element of a Decision Tree relates to the text of the law. This grammar serves a purpose beyond documentation. It is the instrument through which the Decision Tree becomes legally arguable. A Decision Tree without typed anchors is an executable specification of somebody’s reading of the law. A Decision Tree with typed anchors is a legally arguable account of how the law applies, one that courts, auditors, and citizens can engage with on its own normative terms.
The existing standards for structured legal documents (LegalDocML and Akoma Ntoso) provide the infrastructure for this linkage.35 Their FRBR-based identifier systems can address individual sentences and sub-clauses within a structured legislative document. The OLRF’s approach to sub-normative linkage builds on this infrastructure while remaining deliberately neutral about the specific addressing scheme used. What the specification requires is that the link exists, that it is typed, and that it is resolvable. The pluggable resolver architecture underlying the Registry’s linkage model supports Akoma Ntoso, eIDs, XPath-based addressing, and other schemes, allowing different jurisdictions to use the approach best suited to their existing legal document infrastructure.
Sub-normative Linkage Across Three Models
The function of sub-normative linkage shifts across the three models in a way that mirrors the shift in the Decision Tree’s role.
In Model A, sub-normative linkage is verified at construction time. Every element of the tree is checked against its anchor. The linkage serves as the permanent basis for judicial review of the tree itself, and by extension of every determination the tree produces.
In Model B, sub-normative linkage serves as the reference structure against which the Legal Agent’s reasoning is validated. When the agent applies a provision, the validation framework checks whether the agent’s interpretation is consistent with the tree’s anchor for that provision. If the agent invokes a sentence that the tree’s derived_from anchor does not reference, that constitutes a scope deviation. If the agent’s interpretation of a defined term diverges from the tree’s defined_in anchor, that constitutes a reasoning path deviation. The linkage does not constrain the agent’s reasoning. It makes the divergence visible and documentable.
In Model C, sub-normative linkage is the retrospective documentation tool. The agent’s determination is mapped against the tree’s anchor structure after the fact to produce a record of which statutory provisions the agent relied upon and whether its application is consistent with the tree’s interpretation.
Across all three models, the practical consequence is the same: the thread between normative specification and enacted law is not merely present but traceable, at every node, by any lawyer, court, or citizen with access to the statutory text.
The Coverage Map
Sub-normative linkage makes visible the connections between Decision Tree and law. It does not make visible what the Decision Tree leaves out, and why. The Coverage Map addresses this second question.
Every Decision Tree deliberately implements only a part of the norm it refers to. Some provisions require context-dependent weighing of competing factors (proportionality assessments, best-interest determinations) that cannot be reduced to fixed decision logic without losing the flexibility the law intends. Others apply to circumstances with a high level of variation that cannot be handled by a manageable number of rules. And others deliberately grant discretion to the implementing authority. Where a Decision Tree attempts to automate provisions of this kind, it does not faithfully implement the norm. It narrows it, replacing the legislature’s intended openness with rigid logic.
The Coverage Map is a structured document, published alongside the Decision Tree in the Registry, that classifies every element of the implemented norm. Four classifications are defined36.
Implemented marks those portions fully operationalised in the Decision Tree: the conditions, effects, exceptions, and parameters that are explicitly modelled and (in Model A) deterministically evaluated.
Discretionary marks those portions involving the exercise of human judgment: the elements at which the tree generates a Discretion Point escalation rather than a deterministic output.
Excluded marks those portions deliberately not operationalised, for example because they are declaratory, address circumstances outside the system’s scope, or raise legal questions that the responsible authority has decided should be resolved by human officials.
Contested marks those portions whose operationalisation involves an interpretive dispute, whether because the text is ambiguous, judicial opinion is unsettled, or the responsible authority has made an interpretive choice it acknowledges as contestable.
The Coverage Map serves three functions that no other component of the OLRF architecture provides.
For legal and constitutional oversight, it is the instrument of democratic control over the scope of automation. A legislature reviewing an interpretive Decision Tree published by an administrative authority needs to know what has been automated, what has been preserved for human judgment, and what has been deliberately excluded. Without a Coverage Map, the legislature cannot exercise meaningful oversight of whether the authority’s implementation choices are consistent with legislative intent. With it, those choices are explicit, documented, and challengeable through normal mechanisms of legislative oversight.
For courts and auditors, the Coverage Map is the first document to consult when reviewing a challenged automated decision. It tells the court, immediately and with precision, whether the aspect of the norm at issue falls into the Implemented, Discretionary, Excluded, or Contested category. If it is Implemented, the court can examine the Decision Package to verify correctness. If it is Discretionary, it can examine the discretion record. If it is Excluded, it can assess whether the exclusion was appropriate. If it is Contested, the court has before it the implementing authority’s own acknowledgement of interpretive uncertainty, which serves both as evidence and as a potential ground of challenge.
For citizens, the Coverage Map is, when rendered in accessible language, the most honest account of what the system can and cannot do. A citizen whose application was processed automatically and who received an adverse decision needs to know whether the relevant aspect of the norm was automated, and if so, how. The Coverage Map, accessed through the Registry and explained in plain language, is the foundation of meaningful procedural rights in an automated governance environment.
There is a further, less obvious function: the Coverage Map disciplines the process of Decision Tree development itself. The requirement to produce a Coverage Map forces the responsible authority to engage with the norm in its entirety, rather than operationalising the straightforward parts and leaving the difficult parts implicit. In practice, the process of filling in the Coverage Map amounts to a structured legal review of the implementation, conducted at the level of sub-normative detail that paragraph-level documentation cannot support.
Coverage Map Across Three Models
In Model A, the Coverage Map documents the scope of deterministic automation. Elements classified as Implemented are those the tree evaluates. Elements classified as Discretionary are those the tree escalates. Elements classified as Excluded are those the system does not process.
In Model B, the Coverage Map documents the scope of the validation framework. Elements that the agent addresses but that the tree does not cover fall outside the validation framework’s reach, with correspondingly reduced structural verifiability. The Coverage Map tells the court, the auditor, and the citizen where the agent operates with structural oversight and where it operates with reduced oversight.
In Model C, the Coverage Map documents the scope of the audit protocol. Elements covered by the tree produce a structured audit record. Elements not covered produce no structured audit record, which means the agent’s reasoning on those elements is visible only through the agent’s own narrative explanation, not through structural comparison.
In all three models, the Coverage Map makes the responsible authority’s implementation choices visible to the legislature, the courts, and the public. A Coverage Map that classifies every element as fully automated is a political statement. A Coverage Map that classifies many elements as excluded or contested is a different political statement. Both are legitimate. Both are reviewable. The point is that the statement is made publicly and can be challenged.
Deterministic Execution Semantics: Equal Treatment by Design
In the context of the OLRF proposal, determinism does not mean rough consistency, statistical reliability, or merely good engineering practice. It means something stricter: where the same legally relevant facts are presented in the same validated form, every conformant evaluation engine must reach the same result, every time, without deviation.37
This requirement is made possible by the execution semantics of the Decision Tree. These semantics define, fully and explicitly, how evaluation is to proceed: the order in which Conditions are tested, the way overlapping rules are resolved, the treatment of missing or incomplete Facts, the handling and priority of Exceptions, and the manner in which each step is recorded. These semantics form part of the standard itself. Any engine claiming conformance must apply them in the same way, and that claim can be tested against the accompanying test suite.
The importance of deterministic execution reaches directly into the constitutional core of the rule of law. A democratic legal order does not merely aspire to treat like cases alike. It depends on doing so. Equal treatment is not an administrative virtue that may be approximated where convenient. It is one of the basic conditions under which public power remains lawful. Where identical facts lead to different legal outcomes, the problem is not simply one of system quality. It is a failure of legality itself. Arbitrariness enters at precisely the point where law is supposed to exclude it38.
This is why determinism matters. It is the means by which a foundational constitutional commitment is carried from the human world of administration into a world increasingly mediated by software. It does not answer every question. It does not tell us whether the Decision Tree reflects the best interpretation of the law, or even a correct one. Those remain legal and institutional questions, open to legislation, review, challenge, and revision. But it does secure something essential: it ensures that whatever rule has been authoritatively specified is applied in the same way to every case that falls within its scope.
The distinction matters. The content of the norm remains a matter for democratic institutions and, where necessary, for the courts. The uniformity of its execution is a matter for architecture. One concerns legal correctness. The other concerns legal equality in application. Both are indispensable, but they are not the same.
Determinism Across Three Models
The relationship between determinism and the three models must be stated precisely, because it is the most important practical difference between them.
In Model A, determinism is guaranteed by the architecture. The evaluation engine is deterministic. The same facts produce the same outcome. This is the strongest form of the equal treatment guarantee.
In Model B, determinism is approximated and monitored. The Legal Agent’s reasoning is not deterministic (the same facts may produce different reasoning paths on different invocations). The validation against the Decision Tree’s structure provides a consistency check, not a consistency guarantee. The population-level monitoring (described in the chapter on Discretion Points) provides a second layer: if systematic inconsistencies emerge across the agent’s determinations, the monitoring system detects them. The equal treatment guarantee is structural at the validation level and statistical at the population level.
In Model C, determinism is neither guaranteed nor approximated. It is documented. The retrospective audit against the tree provides a benchmark against which consistency can be measured, but it does not enforce it. The equal treatment guarantee depends entirely on the quality and consistency of the agent, with the tree serving only as the benchmark against which consistency is assessed.
This progression (from guaranteed to approximated to documented) is the principal reason why Model A remains the constitutionally appropriate model for bound decisions with deterministic outcomes, and why Model C is not currently deployable for binding legal decisions. The equal treatment guarantee weakens as the model moves from A to C. The gain from moving toward Model B and C (the ability to handle open texture, unstructured fact patterns, and context-dependent interpretation) comes at the cost of reduced determinism. Whether that trade-off is acceptable depends on the legal character of the decision. For a tax calculation, it is not. For a proportionality assessment, it may be. The architecture enables the choice. It does not make it39 40.
Decision Packages: The Right to Reasons in Structured Form
Every evaluation of a Decision Tree against a defined set of Facts produces a Decision Package. This package is not a secondary report generated after the decision has already been made. It is the formal record of the decision as made: a complete, machine-generated, cryptographically signed account of the reasoning path, produced as an intrinsic output of the evaluation process and available to every party with a legitimate interest in understanding, reviewing, or contesting the result.41
The Decision Package brings together several layers of information, each serving a different function within the overall architecture of explanation, review, and proof.
The evaluation path records the sequence in which Conditions were assessed, the result of each assessment, and the Facts on which that assessment depended. It shows how the decision moved through the tree, step by step, and thereby makes the internal logic of the outcome reconstructable as a structured chain of reasoning: this fact mattered, this condition was met or not met, this branch was followed, and this consequence therefore resulted.
The subsumption graph captures the relationship between factual inputs and legal predicates. It shows not only which Facts were present, but how those Facts contributed to the fulfilment, non-fulfilment, or irrelevance of particular Conditions, and how those Conditions combined to produce the final Effect. In practical terms, this is the formalisation of legal reasoning itself: the act of subsumption by which facts are classified into legal categories and legal consequences follow from that classification.
The legal anchors connect each relevant element of the evaluation to the specific provisions of the statutory text from which they derive. The decision does not float free as a technical artefact. Each part remains tied to a recognisable legal source. This allows the citizen to trace the decision back to the law that governs them, the court to verify the statutory basis of each step, and the auditor to confirm that the Decision Tree has not silently departed from the enacted norm.
The discretion record (where applicable) documents that deterministic evaluation reached its lawful limit, identifies the human decision-maker to whom the matter was escalated, records the basis of that person’s authority, and captures both the criteria applied and the reasons given. The significance of this record is considerable: it shows that discretion was neither concealed nor simulated by the machine, but exercised openly by a person authorised to do so under the terms of the norm.
The effects record captures the final legal consequences produced by the evaluation for the specific case at hand: grant, refusal, calculation, obligation, referral, or any other formally defined result. These effects are expressed in structured and typed form so that they can be communicated, reviewed, appealed, or enforced without ambiguity.
The provenance record ties the Decision Package to the exact version of the Decision Tree under which the evaluation was conducted, using the Registry identifier and the cryptographic hash of the signed artefact. This secures the temporal integrity of the decision: it ensures that one can later establish, with precision, which version of the normative specification was in force at the relevant moment. Just as courts may need to determine which statutory text applied at a particular date, they must also be able to determine which normative specification governed the automated application of that text.
The cryptographic signature seals the entire Decision Package, binding together the evaluation service, the Decision Tree version, the submitted Facts, and the resulting Effects. Any later alteration to any material element becomes detectable. The signature performs the function once served by the official seal on an administrative act: it marks the record as authentic, protects its integrity, and gives it evidentiary weight in any later review or judicial proceeding. The signature must be a legally recognised trust service signature or seal issued within a regulated trust framework, capable of carrying legal force across institutional boundaries.42
Decision Packages Across Three Models
The Decision Package format is constant across all three models. What varies is the content.
In Model A, the Decision Package records a deterministic evaluation: every condition tested, every branch taken, every fact relied upon, every anchor invoked. The evaluation path is structural and complete. A court can reproduce the determination by re-running the tree against the same facts.
In Model B, the Decision Package records a validated agent determination. It contains the agent’s determination, the validation result (confirmed or deviation), the deviation classification (if applicable), the agent’s reasoning narrative, and the tree’s structural evaluation for comparison. The evaluation path is partly structural (the validation) and partly narrative (the agent’s reasoning). A court can verify the validation but must assess the agent’s reasoning on its own terms.
In Model C, the Decision Package records an approved agent determination with a retrospective audit record. It contains the agent’s determination, the human approver’s decision, the retrospective mapping against the tree’s structure, and the agent’s reasoning narrative. The structural component is the weakest. A court can verify the retrospective mapping and the approval record, but the agent’s reasoning is accessible only as narrative.
This progression (from fully structural to partly narrative to predominantly narrative) mirrors the progression in determinism. It is the reason why judicial reviewability is richest in Model A and most limited in Model C, and why the choice of model must be calibrated to the constitutional weight of the decision.
Taken together, these elements amount to something that automated governance has largely lacked until now: a complete, verifiable, and legally structured account of how a machine-mediated decision was reached. The Decision Package makes that process legible across institutional boundaries. It is meaningful to lawyers because it preserves legal reasoning in formal form. It is auditable by courts because it records the normative and factual basis of the outcome. It can be rendered intelligible to citizens through an explanation layer that translates the structured record into plain language. And in Model A, it is reproducible by any conformant engine given the same inputs and the same Decision Tree. The Decision Package is not merely a matter of good administrative practice. It is the technical expression of the constitutional right to reasons43.
Relationship to LegalDocML and Akoma Ntoso --- Complementary, Not Competitive
A persistent source of confusion in discussions around Law as Code is the relationship between machine-executable legal logic and the existing standards for the representation of legal documents. This confusion is understandable, as both domains deal with the formalisation of law, and both use structured data formats to represent legal content. But the confusion is consequential, because it leads to the false conclusion that a decision to adopt LegalDocML or Akoma Ntoso44 is a decision about Law as Code, or vice versa.
LegalDocML and Akoma Ntoso are standards for the representation of legal text.³⁰ They specify how statutes, regulations, court decisions, and parliamentary documents should be structured in XML: how their hierarchical organisation should be encoded, how citations should be expressed, how document identity should be managed through FRBR identifiers, and how metadata should be attached. They represent the state of the art in the digital representation of legal documents as documents.
The OLRF Decision Tree is not a document. It is a normative specification. It does not represent the text of a statute. It represents the rules that the text establishes, in a form that can be applied to facts to produce legal determinations. These are fundamentally different things, and no extension of LegalDocML can bridge the gap between them, not because those standards are inadequate for their purpose, but because their purpose is different.
The relationship between the OLRF and these standards is therefore one of complementarity, not competition. LegalDocML and Akoma Ntoso provide the structured representation of the statutory text that the Decision Tree references through its legal anchors. The FRBR identifiers that these standards assign to individual provisions are precisely the identifiers that the OLRF’s sub-normative linkage system uses to connect each element of the Decision Tree to the specific textual provision from which it derives. A jurisdiction that has already adopted Akoma Ntoso for the publication of its legislative documents has already done a significant part of the work required to support fine-grained OLRF legal anchors. The two investments are not redundant. They are sequential.
The practical implication is straightforward: the OLRF does not require any jurisdiction to abandon, replace, or modify its existing legal document standards. It requires only that those standards be present, and that the identifiers they provide be used as reference points in the Decision Tree’s legal anchors. For jurisdictions that have not yet adopted structured legal document standards, the adoption of LegalDocML and the development of OLRF Decision Trees are complementary initiatives, best pursued in parallel, that will both contribute to a governance environment in which the text of the law and the logic of the law are formally, verifiably, and permanently connected.
That connection between the democratic act of legislation and the technical act of automated application is the foundational promise of the OLRF. The Decision Tree, with its typed elements, its sub-normative anchors, its Coverage Map, its deterministic execution semantics, and its signed Decision Packages, is the instrument through which this promise is proposed to be made real.
Footnotes
-
The structural gap between enacted law and its software implementation, and the constitutional implications of private, unaccountable translation, was first systematically analysed by Citron, D.K., “Technological Due Process,” Washington University Law Review, Vol. 85, No. 6, 2008, pp. 1249—1313 ↩
-
New Zealand Government CDDO, Rules as Code Discovery Report, 2018 ↩
-
Maurer, H. and Waldhoff, C., Allgemeines Verwaltungsrecht, 20. Aufl., C.H. Beck 2020, § 24 Rn. 9—26. The OLRF’s interpretive publication mode transfers this established legal concept into the domain of machine-executable normative specifications. ↩
-
Wischmeyer, T., “Regulierung intelligenter Systeme,” Archiv des öffentlichen Rechts (AöR), Bd. 143, 2018, S. 1—66. ↩
-
An early practical demonstration that an entire statute could be represented as executable logic was Sergot, M.J. et al., “The British Nationality Act as a Logic Program,” Communications of the ACM, Vol. 29, No. 5, 1986, pp. 370—386. Sergot et al. proposed the use of and/or trees to capture the overall logical structure of a statute, with further clauses determining the conditions under which higher-level predicates hold. The OLRF’s Decision Tree is a direct descendant of this approach, extended with typed facts, sub-normative linkage, discretion points, and cryptographic provenance. ↩
-
Bench-Capon, T.J.M. et al., “A History of AI and Law in 50 Papers: 25 Years of the International Conference on AI and Law,” Artificial Intelligence and Law, Vol. 20, 2012, pp. 215—319 (documenting how the field progressively identified which structural elements of legislation must be captured for a formal representation to be legally meaningful). ↩
-
Prakken, H. and Sartor, G., “Law and Logic: A Review from an Argumentation Perspective,” Artificial Intelligence, Vol. 227, 2015, pp. 214—245. ↩
-
Eubanks, V., Automating Inequality: How High-Tech Tools Profile, Police, and Punish the Poor, St. Martin’s Press 2018, Chapters 2 and 4, documenting how the classification of circumstances in automated welfare systems (whether a living arrangement counts as “shared household,” whether an income source counts as “regular employment”) determines outcomes in ways that are invisible to the citizen and largely unreviewable by courts ↩
-
Amnesty International, “Xenophobic Machines: Discrimination through Unregulated Use of Algorithms in the Dutch Childcare Benefits Scandal,” (Toeslagenaffaire) Report, October 2021 ↩
-
Allen, L.E., “Symbolic Logic: A Razor-Edged Tool for Drafting and Interpreting Legal Documents,” Yale Law Journal, Vol. 66, No. 6, 1957, pp. 833—879 ↩
-
Kowalski, R.A., “Legislation as Logic Programs,” in: Bankowski, Z. et al. (eds.), Informatics and the Foundations of Legal Reasoning, Kluwer 1995, pp. 325—356. Kowalski shows that the apparently linear structure of statutory text conceals a deeply recursive logical architecture in which conditions, exceptions, and cross-referential definitions interact in ways that sequential reading cannot reliably resolve. The OLRF’s requirement that each condition carry a typed legal anchor is designed to make this recursive structure explicit and verifiable. ↩
-
The distinction between bound determinations (gebundene Entscheidungen), indeterminate legal concepts (unbestimmte Rechtsbegriffe), and proportionality assessments (Verhältnismäßigkeitsprüfungen) is a foundational taxonomy of German administrative law, with direct implications for the permissible degree of automation. See: Maurer, H. and Waldhoff, C., Allgemeines Verwaltungsrecht, 20. Aufl., C.H. Beck 2020, § 7 Rn. 26—60 (unbestimmte Rechtsbegriffe) and § 7 Rn. 1—25 (Ermessen) ↩
-
Berman, D.H. and Hafner, C.L., “Representing Teleological Structure in Case-Based Legal Reasoning: The Missing Link,” Proceedings of the Fourth International Conference on Artificial Intelligence and Law (ICAIL), ACM 1993, pp. 50—59 ↩
-
Sartor, G., “Defeasibility in Legal Reasoning,” in: Bankowski, Z. et al. (eds.), Informatics and the Foundations of Legal Reasoning, Kluwer 1995, pp. 119—157 ↩
-
Prakken, H., Logical Tools for Modelling Legal Argument: A Study of Defeasible Argumentation in Law, Kluwer 1997, Chapters 2—4 ↩
-
Merigoux, D., Chataing, N., and Protzenko, J., “Catala: A Programming Language for the Law,” Proceedings of the ACM on Programming Languages 5(ICFP), 2021. See also: Lawsky, S., “A Logic for Statutes,” Virginia Tax Review 40(1), 2020 (the formal foundation of default logic for statutory reasoning on which Catala builds) ↩
-
Ossenbühl, F., “Rechtsverordnung,” in: Isensee, J. and Kirchhof, P. (eds.), Handbuch des Staatsrechts der Bundesrepublik Deutschland, Bd. V, 3. Aufl., C.F. Müller 2007, § 103. Ossenbühl analyses the constitutional boundary between permissible delegation (the legislature defines the framework, the executive fills in the values) and impermissible delegation (the legislature transfers the normative decision itself). The OLRF’s delegated_by anchor operationalises this boundary: a Parameter without a valid delegation anchor is a value without a constitutional basis, detectable by any auditor or court with access to the Registry. ↩
-
In EU law, Art. 22 GDPR establishes the right not to be subject to a decision based solely on automated processing that produces legal effects or similarly significantly affects the data subject. ↩
-
Martini, M. and Nink, D., “Wenn Maschinen entscheiden: Vollautomatisierte Verwaltungsverfahren und der Persönlichkeitsschutz,” NVwZ-Extra 10/2017, pp. 1—14 (analysing the conditions under which AI assistance at discretion points is compatible with both the German § 40 VwVfG and EU Art. 22 GDPR) ↩
-
The use of executable specifications for legislative impact assessment has been demonstrated in practice by PolicyEngine (US/UK), which enables policymakers to simulate the population-level effects of tax and benefit reforms by running proposed parameter changes against the complete rules engine. See: PolicyEngine, https://policyengine.org; for the French precedent: LexImpact, developed by the French Assemblée Nationale in collaboration with OpenFisca, which allowed members of parliament to simulate the fiscal impact of proposed amendments during the 2019 budget debate (beta.gouv.fr, “LexImpact: Simuler l’impact de la loi”, 2019). The OLRF’s simulation tests extend this principle from parameter changes to structural changes in the Decision Tree itself. ↩
-
The dual function of the test suite (verification of the tree and baseline for agent certification) creates a constitutional feedback loop. If the test suite is inadequate (too few edge cases, missing exception paths, no escalation scenarios), it undermines not only the quality of the tree but also the quality of the certification, because agents are certified against a test that does not adequately represent the norm’s complexity. The responsible authority therefore has a constitutional incentive to make the test suite as comprehensive as possible: a weak test suite weakens the entire accountability chain, from the tree through the certification to the individual determination. This incentive structure is by design. It ensures that the investment in testing pays dividends at every level of the architecture. ↩
-
The absence of rigorous evaluation frameworks in AI and Law research is documented in the meta-analyses by Conrad and Zeleznikow (2013, 2015), who found that the majority of publications in the field contain no evaluation whatsoever. Merigoux (2024) identifies this as a structural consequence of the field’s pursuit of all-encompassing systems: a general-purpose legal model cannot be meaningfully evaluated, because no benchmark can capture its intended scope. The OLRF’s test suite architecture, with its six named categories (ordinary cases, edge cases, exception paths, Discretion Point escalation, regression, simulation) and its dual function as verification instrument and certification baseline, is designed to provide exactly the domain-specific, benchmark-based evaluation framework that the field has lacked. See: Merigoux, D., op. cit., pp. 8 ff.; Conrad, J. G. and Zeleznikow, J., “The Role of Evaluation in AI and Law”, Proceedings of ICAIL 2015, pp. 181 ff. ↩
-
Morris, J., “Blawx: Web-based user-friendly Rules as Code”, Proceedings of the CEUR Workshop 2022, Vol. 3193; Morris, J., “Constraint Answer Set Programming as a Tool to Improve Legislative Drafting: A Rules as Code Experiment”, Proceedings of the Eighteenth International Conference on Artificial Intelligence and Law (ICAIL), 2021; Canada School of Public Service / Treasury Board of Canada Secretariat, “Rules as Code in Canada: Summary of Experiments and Lessons Learned”, OECD Observatory of Public Sector Innovation 2024; source code at https://github.com/Lexpedite/blawx (open source). ↩
-
Merigoux et al. (2021), op. cit. The French government adopted Catala in 2023 for the rewriting of the income tax computation system; in 2023 the French digital government agency listed Catala as officially recommended open-source software ↩
-
OMG, Decision Model and Notation (DMN) Specification, Version 1.3, 2019. ↩
-
Van Binsbergen, L.T., Liu, L.-C., van Doesburg, R., and van Engers, T., “eFLINT: A Domain-Specific Language for Executable Norm Specifications,” Proceedings of the 19th ACM SIGPLAN International Conference on Generative Programming: Concepts and Experiences (GPCE 2020), ACM, 2020, pp. 124—136. For reflections on the language’s evolution and design decisions across multiple application domains: van Binsbergen, L.T. et al., “Reflections on the Design, Applications and Implementations of the Normative Specification Language eFLINT,” arXiv:2511.12276, 2025. ↩
-
Legalese Pte., L4: A Domain Specific Language for Legal, https://legalese.github.io/doc/dsl. See also: Wong, M.E. et al., “L4: Towards an Accessible Domain Specific Language for Legal,” Working Paper, Singapore Management University, 2022 ↩
-
OASIS, LegalRuleML Core Specification, Version 1.0, Committee Specification 01, 2013. ↩
-
OpenFisca: https://openfisca.org. See also: OECD, “Cracking the Code: Rulemaking for Humans and Machines,” OECD Digital Government Studies, Paris 2020 ↩
-
PolicyEngine, https://policyengine.org; source code at https://github.com/policyengine (AGPL-3.0). PolicyEngine Core documentation at https://policyengine.github.io/policyengine-core/. For the Downing Street engagement: PolicyEngine Blog, “PolicyEngine at 10 Downing Street”, 2023. For the NBER partnership: PolicyEngine TAXSIM, https://github.com/PolicyEngine/policyengine-taxsim. ↩
-
MinBZK (Netherlands Ministry of the Interior), RegelRecht Proof of Concept, https://github.com/MinBZK/poc-machine-law (EUPL-1.2); Ecosystem documentation at https://minbzk.github.io/regelrecht/. The project was previously known under several names including “PoC Machine Law”, “Van wet naar digitale werking”, and “Law as Code”. It builds on the regels.overheid.nl platform, documented at https://github.com/MinBZK/regels.overheid.nl. ↩
-
Breidenbach, S., Was Gesetze sein könnten: Mit Methode zum guten Gesetz, C.H. Beck 2025. See also: Rulemapping Group, White Paper: Rulemapping Method and Rule AI, 2026 (https://rulemapping.com). ↩
-
For the foundational analysis of why paragraph-level linking is insufficient for legal accountability of automated systems: Bench-Capon, T.J.M. and Sergot, M.J., “Towards a Rule-Based Representation of Open Texture in Law,” in: Walter, C. (ed.), Computer Power and Legal Language, Quorum Books 1988 ↩
-
The five anchor types were developed as part of the OLRF normative specification v0.3. For the theoretical foundations of typed normative derivation in computational law: Prakken, H. and Sartor, G., “Law and Logic: A Review from an Argumentation Perspective,” Artificial Intelligence, Vol. 227, 2015, pp. 214—245. ↩
-
OASIS, Akoma Ntoso Version 1.0, OASIS Standard, 2018. For the FRBR identifier model: IFLA, Functional Requirements for Bibliographic Records: Final Report, 1998 (amended 2009). For technical introduction: Palmirani, M. and Vitali, F., “Akoma Ntoso for Legal Documents,” in: Sartor, G. et al. (eds.), Legislative XML for the Semantic Web, Springer, 2011, pp. 75—100 ↩
-
The requirement that the scope of automation be explicitly documented and democratically reviewable derives from the Wesentlichkeitstheorie (essential matters doctrine) of German constitutional law: the principle that the legislature must itself make the essential normative choices and may not delegate them to the executive without specifying content, purpose, and scope. See: BVerfGE 49, 89 (Kalkar I, 1978); BVerfGE 83, 130 (Josefine Mutzenbacher, 1990) ↩
-
For the constitutional significance of deterministic execution in the context of equal treatment: BVerfGE 149, 407 (2018), confirming that the Wesentlichkeitstheorie requires the legislature to make essential normative choices. For the formal treatment of deterministic evaluation semantics in rule-based legal systems: Sergot, M.J. et al., “The British Nationality Act as a Logic Program,” Communications of the ACM, Vol. 29, No. 5, 1986, pp. 370—386. ↩
-
In the philosophy of law, the requirement of congruence between the rules as announced and their actual administration is one of Lon Fuller’s eight principles of legality, whose violation constitutes a failure of the “inner morality of law”: Fuller, L.L., The Morality of Law, Yale University Press 1964, pp. 81—91 ↩
-
The trade-off between deterministic consistency and the ability to handle open texture is the central tension in the computational law literature. Its theoretical foundation is Hart, H.L.A., The Concept of Law, Oxford University Press 1961 (2nd ed. 1994), Chapter VII, Section 1, where Hart establishes that legal rules possess an “open texture”: a core of settled meaning surrounded by a penumbra of uncertainty in which reasonable people may disagree. ↩
-
Diver, L., “Against Algorithmic Clarity: Law Beyond Specification,” International Journal for the Semiotics of Law, Vol. 38, 2025 (arguing that the specificity demanded by algorithmic systems undermines the principled vagueness of legal concepts, and that this vagueness is not a flaw to be corrected but a jurisprudential strength that enables law to remain responsive to moral and social development). ↩
-
For the constitutional right to reasons (Begründungspflicht) in German administrative law: § 39 VwVfG (requirement to state reasons for administrative acts). For the relationship between automated decision-making and the right to explanation: Wachter, S. et al., “Why a Right to Explanation of Automated Decision-Making Does Not Exist in the General Data Protection Regulation,” International Data Privacy Law, Vol. 7, No. 2, 2017, pp. 76—99 (arguing that the GDPR provides a right to be informed about the logic involved, not a right to explanation of individual decisions, a gap that the OLRF Decision Package is designed to fill). ↩
-
eIDAS Regulation (EU) No. 910/2014, Articles 25—34 (electronic signatures and seals). For the trust framework context: European Commission, EU Digital Identity Framework, Regulation (EU) 2024/1183 amending eIDAS. ↩
-
The constitutional right to reasons (Begründungspflicht) in automated governance faces a structural challenge that the Decision Package is designed to resolve. In German administrative law, § 39 VwVfG requires that every administrative act be accompanied by a statement of the essential factual and legal reasons on which it is based. In EU administrative law, the duty to give reasons under Art. 296 TFEU has been extended by the CJEU to automated decisions: in Case C-203/22 (Dun & Bradstreet Austria, 2024), the Court held that the right to meaningful information about the logic involved in automated decision-making cannot be satisfied by the mere communication of a mathematical formula or by a detailed description of all steps in the processing, but requires an explanation that the affected individual can understand. Critically, Hildebrandt has argued that an explanation of how a system reached its conclusion is not the same as a justification that the conditions set by law for the decision are fulfilled: “Explaining how the system reached a conclusion is far different from showing if the conditions set by law for that decision are fulfilled.” See: Hildebrandt, M., “Algorithmic Regulation and the Rule of Law,” Philosophical Transactions of the Royal Society A, Vol. 376, 2018. The Decision Package addresses this distinction directly. In Model A, it provides not merely an explanation (how the system processed the data) but a justification (which statutory conditions were tested, which facts satisfied them, and which legal consequence followed). In Models B and C, the justification is progressively more narrative and less structural, which is itself an argument for matching the model to the constitutional weight of the decision. See also: Olsen, H.P., Slosser, J.L., and Hildebrandt, M., “What’s in the Box? The Legal Requirement of Explainability in Computationally Aided Decision-Making in Public Administration,” in: Micklitz, H.-W. et al. (eds.), Constitutional Challenges in the Algorithmic Society, Cambridge University Press 2022, pp. 219—240 (proposing an “administrative Turing test” for automated explanations: the explanation produced by the system must meet the same standard that would be required of a human decision-maker under administrative law). ↩
-
Akoma Ntoso: UN/DESA, Akoma Ntoso Version 1.0, OASIS Standard, 2018 ↩