Chapter 12
The Rule of Law in the Age of Executable Norms
Last updated: 2026-04-10 Open for review
“When many hands contribute to an outcome, the conventional frameworks for assigning responsibility break down. No single actor is responsible, and so, effectively, no one is.” --- Helen Nissenbaum, Accountability in a Computerized Society, Science and Engineering Ethics, 1996
What the Rechtsstaat Requires of Automated Governance
Every democratic legal order rests on a set of principles designed to prevent the arbitrary exercise of public power. In the German constitutional tradition, these principles are collected under the concept of the Rechtsstaat. In the French tradition, the equivalent is the État de droit. The specific principles vary in formulation across jurisdictions, but their substance is shared. Lon Fuller identified eight of them: law must be general, publicly promulgated, prospective, clear, non-contradictory, stable, possible to comply with, and administered as announced1. These are the procedural requirements. They ensure that people can know the rules, understand them, and act accordingly. Beyond these, every constitutional order adds substantive requirements: that law respect fundamental rights, that its application be proportionate to its aims, and that the state treat comparable cases comparably. Together, these procedural and substantive requirements form the constitutional standard against which every exercise of public power must be measured. This standard applies with full force to automated systems. It is not relieved, adapted, or otherwise modified because a decision was produced by software rather than by a human official.
Automated governance has not created new constitutional requirements. It has made existing ones harder to fulfil and easier to violate. The characteristic failures of automated administration (opaque reasoning, inconsistent outcomes, the systematic exclusion of individual circumstances) are not inventions of the digital age. They are familiar failures of governance that technology has made possible at unprecedented scale and speed, which keeps on rising exponentially with AI entering the scenery. A system that applies a norm inconsistently across comparable cases violates the principle of equal treatment, whether the inconsistency is caused by a biased human, a misconfigured algorithm, or a poorly trained language model. A system that cannot explain why it reached a particular outcome violates the duty to give reasons, whether the reasoning was performed by a human mind or a statistical model. A system whose normative basis is treated as a trade secret violates the requirement of public promulgation, whether the secrecy is maintained by a government department or a software vendor. The constitutional obligations are the same. What changes is the infrastructure through which they must be met.
The three models introduced in Part I make this challenge more precise. Under Model A (deterministic evaluation), the constitutional risk is concentrated in the Decision Tree itself: if the tree is wrong, every outcome it produces is wrong. Under Model B (guided evaluation), the constitutional risk is distributed between the tree and the Legal Agent: the agent’s subsumption may deviate from the tree’s expected path, and the validation framework must catch deviations that cross constitutional thresholds. Under Model C (autonomous legal reasoning), the constitutional risk shifts to the retrospective audit: the agent reasons directly, and the question is whether the audit protocol is rigorous enough to detect constitutional violations after they have occurred rather than preventing them in advance. The Rechtsstaat requirements are constant across all three models. The mechanisms through which they are fulfilled, and the points at which they are most likely to fail, are different.2
The Indeterminacy Objection
Any architecture that claims to translate law into executable form must confront a foundational critique that the AI and Law community has discussed for decades. The argument, developed most sharply by Berman and Hafner3, is that legal indeterminacy is not an engineering problem to be solved by developers. It is a structural feature of how law functions.
One of the earliest and most instructive attempts to translate legislation into formal logic was the 1986 project by Sergot, Sadri, Kowalski, and others, who encoded the British Nationality Act as an executable logic program4. The Act was chosen precisely because it appeared unusually well suited to formalisation: its structure is largely conditional, its categories are relatively well defined, and its outcomes are mostly deterministic. Yet even this statute could not be fully captured. The researchers found that key terms in the Act carried meanings that depended on context, on judicial interpretation, or on factual assessments that no formal rule could anticipate. These terms had to be resolved by human judgment outside the logic program. The formal system could process the Act’s structure. It could not, by itself, determine what the Act’s words meant in every case.
Bench-Capon and Sergot gave this problem a name: open texture.5 The term describes a property inherent in legal language. Legal categories (“reasonable”, “habitual residence”, “good character”) must be general enough to apply across an open-ended range of future cases. This generality is not a defect. It is what makes law adaptable. But it means that at the boundary between the legal category and the real-world situation it is applied to, there will always be cases where the classification is genuinely uncertain, not because the drafter was careless, but because no fixed definition can anticipate every situation that the future will produce. This open texture cannot be engineered away. It is part of how legal language works.
Branting, surveying the field three decades after the early formalisation attempts, confirmed that two fundamental obstacles remained unresolved.6 First, there is no scalable method for producing logical representations of legal texts that are accepted as authoritative by the legal community. Creating a formal model of a single statute is a research project; creating formal models of an entire legal domain, and keeping them current, remains beyond practical reach. Second, the terms that legal rules use (“employee”, “residence”, “dependent”) carry meanings shaped by decades of judicial interpretation, administrative practice, and social convention. Translating these terms into the precise predicates that a formal system requires means stripping away exactly the contextual richness that gives them their legal meaning.
There is a deeper dimension still. Legal reasoning is not merely about matching facts to predicates. It is about the purposes that rules serve and the values they instantiate. Berman and Hafner termed this the teleological structure of legal reasoning. Bench-Capon and Sartor formalised it as the role of theories and values in legal argumentation. A deterministic Decision Tree that captures the conditional structure of a provision but not the legislative purpose behind it produces a representation that is formally correct but normatively incomplete. It can tell you what the rule says. It cannot tell you what the rule is for, and therefore cannot guide the application of the rule in cases where its purpose and its literal terms point in different directions.
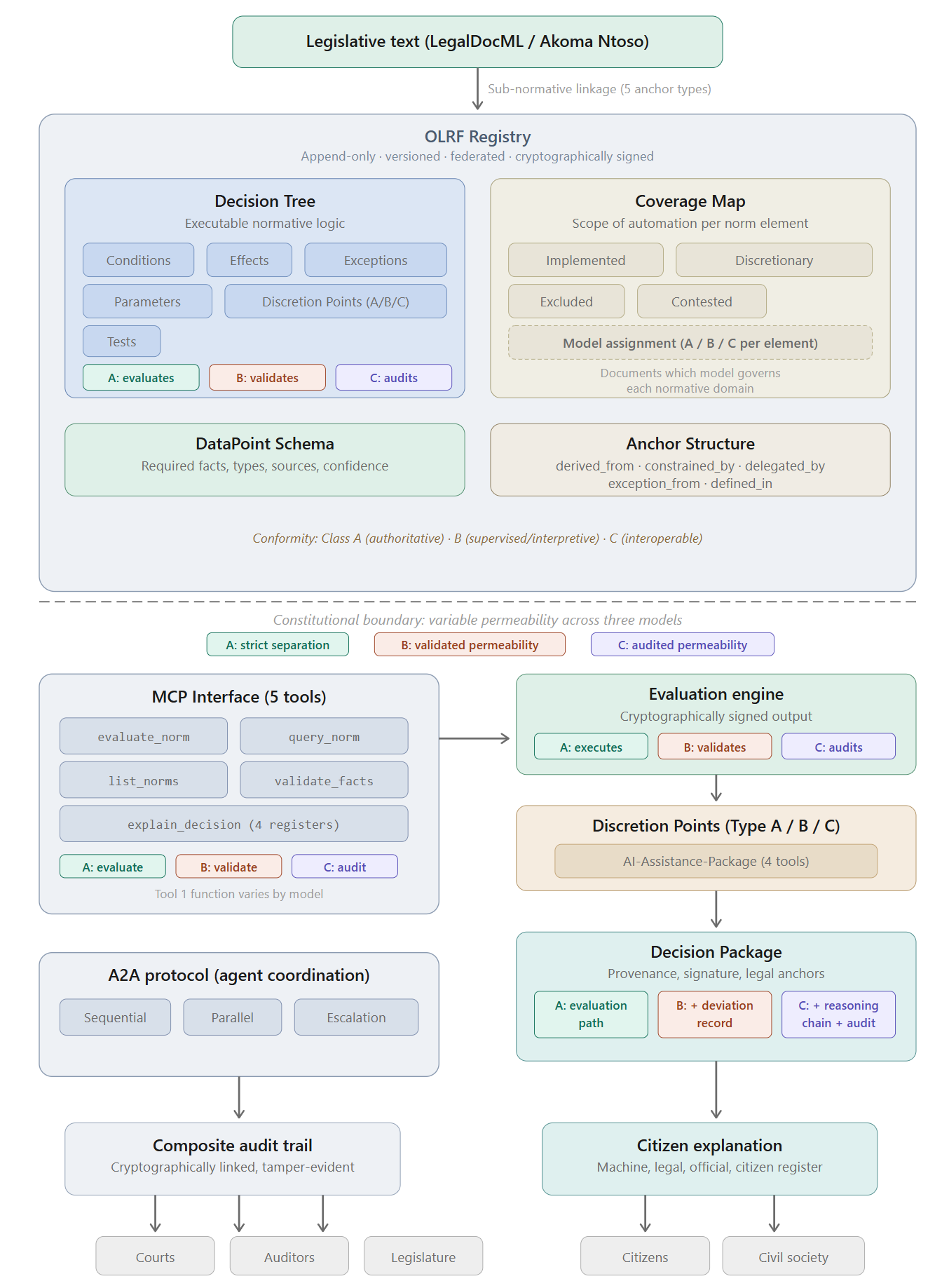
The OLRF does not claim to have solved this problem. It claims to have given it an architectural address. That address has two parts: the dual publication model and the three-model architecture.
The dual publication model (in which the Decision Tree sits alongside, rather than replaces, the authoritative legal text) is the primary structural response. The human-readable text remains the primary legal source. The Decision Tree is understood as an interpretation, subject to revision and contestation, not as the law itself. The sub-normative linkage system makes this relationship explicit at every node: each element of the Decision Tree is anchored to the specific passage of legislative text from which it derives, enabling any lawyer, court, or citizen to assess whether the derivation is correct. Where the text is ambiguous, where judicial opinion is divided, where the legislative purpose and the literal terms are in tension, the Coverage Map classifies the affected elements as “contested”, documenting the interpretive choice and making it publicly challengeable7.
The three-model architecture is the second, and more fundamental, response. It addresses the indeterminacy objection not by claiming that all law can be rendered deterministic, but by providing different architectural modes for different degrees of legal determinacy. Model A is appropriate where the norm is fully deterministic: all conditions are formally specifiable, all outcomes are calculable, and no open-textured judgment is required. In German legislation, this is the terrain of §35a VwVfG, of pension calculations, of threshold-based benefit determinations. Model B is appropriate where the norm contains elements that require subsumption under legal concepts whose application is guided but not fully predetermined: the Legal Agent applies the concept, the Decision Tree validates the result, and deviations are classified and documented. This is the terrain of many regulatory assessments, where professional judgment is required but the range of acceptable outcomes is bounded. Model C is appropriate where the norm is genuinely open-textured, where the legislative purpose and the contextual circumstances must be weighed against each other, and where no Decision Tree can anticipate the full range of relevant considerations. Here the agent reasons directly, and the Decision Tree functions as a retrospective audit protocol8.
The indeterminacy objection is therefore not refuted. It is absorbed into the architecture. Hart’s open texture, Berman and Hafner’s teleological dimension, and Branting’s scalability concern are not treated as obstacles to the OLRF but as the reasons why the OLRF requires three models rather than one. A single-model architecture that insisted on deterministic evaluation for all norms would indeed deserve the critique that it cannot capture the full meaning of law. A three-model architecture that assigns each norm to the model appropriate to its degree of determinacy, and that documents that assignment in the Coverage Map, responds to the critique by making the degree of formalisation itself a visible, contestable, and democratically accountable decision9.
The Risk of Normative Displacement
The dual publication model faces an empirical challenge that the architecture alone cannot resolve. The history of standards suggests that executable representations tend to become the operative reality regardless of what the formal hierarchy says. If administrations, AI systems, and autonomous agents all interact with law exclusively through the Decision Tree, then the textual layer risks becoming a ceremonial artefact rather than a living source of normative meaning. The map, as it were, displaces the territory.
The OLRF’s architecture contains several structural safeguards against this displacement, but it would be dishonest to claim that they eliminate the risk.
The sub-normative linkage system is the first safeguard. Because every element of the Decision Tree is anchored to the specific legislative text from which it derives, the text is not merely a parallel document that sits beside the tree. It is structurally embedded in the tree’s own accountability model. A court reviewing a Decision Tree element does not assess whether the tree is internally consistent. It assesses whether the element correctly reflects the legislative text it claims to implement. This forces continuous engagement with the text, not just the tree.
The Coverage Map is the second safeguard. By classifying elements as “contested”, the Coverage Map formally acknowledges points at which the Decision Tree’s interpretation of the text is disputable. These are the points at which the text and the tree may diverge, and the Coverage Map makes that potential divergence visible to every actor in the system: legislators, courts, auditors, citizens.
The Registry’s version control is the third safeguard. Every change to the Decision Tree is a new Registry entry, traceable and attributable. If the tree evolves away from the text over time (through successive amendments, parameter adjustments, or re-interpretations), the version history makes that drift visible and reconstructable.
The three-model architecture introduces a fourth safeguard that the original single-model design did not possess. Under Models B and C, the Legal Agent’s reasoning is not confined to the Decision Tree. In Model B, the agent subsumes facts under legal concepts drawn from the statutory text and from case law, and the validation framework checks whether that subsumption is consistent with the tree. In Model C, the agent reasons directly from the statutory text, and the audit protocol compares the result against the tree. In both cases, the statutory text remains an active input to the decision-making process, not merely a background reference. The risk of normative displacement is therefore structurally lower in Models B and C than in Model A, because the agent’s engagement with the text creates a continuous pull away from the tree and back toward the law it implements. This is a constitutional benefit of the multi-model architecture that was not anticipated in its original design10.
Whether these safeguards are sufficient to sustain a genuine dialectic between text and tree, rather than a slow eclipse of the former by the latter, is an empirical question. It depends on institutional practice: on whether courts continue to reason from the text rather than the tree, on whether legislatures exercise their oversight function through the Coverage Map, and on whether the legal profession maintains its capacity to engage with law as text rather than as executable specification. The OLRF creates the architectural conditions for this dialectic. It cannot guarantee that the institutional culture will sustain it.
The Ethics of Efficient Enforcement
The constitutional analysis of automated governance must also confront a question that is rarely asked in technical architectures but that has profound implications for the relationship between law and society: what happens when law can be enforced with dramatically higher efficiency?
There is a serious argument in legal theory and political philosophy that law functions, in part, because it is not uniformly enforced at one hundred percent11. Selective enforcement creates space for prosecutorial discretion, for de minimis tolerance, for the practical accommodation of social norms that have evolved beyond the statute book. A parking regulation that is enforced sporadically operates differently, in its social effect, from one that is enforced automatically and without exception through sensor networks and automated penalty systems. The legal text is identical. The governance reality is fundamentally different.
The OLRF architecture, by making norm application more efficient, more consistent, and more comprehensive, increases the effective enforcement rate of every norm it implements. This is, in most respects, a constitutional virtue: equal treatment requires that similar cases be treated alike, and selective enforcement is one of the primary mechanisms through which unequal treatment enters administrative practice. But it also raises a question that the architecture must acknowledge: does the system preserve the space for the kind of structured mercy that democratic societies have historically relied upon?
The answer lies in the Discretion Point architecture and the Coverage Map, but only if they are used for this purpose. A legislature that enacts a norm with a discretionary element has, whether or not it articulates this explicitly, created space for the administering authority to temper the norm’s application in individual cases. The Discretion Point preserves that space architecturally. The Coverage Map makes its boundaries visible. But a Decision Tree that models every element of a norm as “implemented” and leaves no Discretion Points, no excluded elements, and no contested classifications, has effectively chosen maximum enforcement. Whether that choice is constitutionally appropriate is a question for the responsible authority and the legislature, not for the architecture. What the architecture can do, and what the OLRF does, is make the choice visible. A Coverage Map that classifies every element as fully automated is a political statement: it says that the responsible authority has decided that this norm should be applied without exception, without individual mitigation, and without human judgment at any point. The legislature, the courts, and the public can then assess whether that political statement is consistent with the constitutional order.
The three-model framework adds a further dimension to this analysis. The assignment of a norm to Model A (deterministic evaluation) rather than Model B (guided evaluation) or Model C (autonomous reasoning) is itself a decision about enforcement intensity. Model A enforces with maximum consistency but minimum sensitivity to context. Model C permits maximum contextual sensitivity but introduces the risk that consistency erodes. Model B occupies the middle ground: the agent can adapt to context within the corridor that the validation framework permits. The choice of model is therefore not merely a technical decision about system architecture. It is a normative decision about the balance between consistency and contextual responsiveness that the constitutional order requires for a given type of decision. The Coverage Map must document not only which elements are automated, but under which model they are automated, so that the normative implications of that choice become visible to democratic oversight12.
The OLRF’s Constitutional Argument
The consequence of this discussion is that the constitutional case for the OLRF cannot be reduced to a single claim about transparency, consistency, or technical control. The architecture is asked to do something more demanding. It must preserve legality under conditions in which law is increasingly specified, applied, and enforced through software. That means confronting not only the familiar pathologies of opacity and fragmentation, but also the harder questions raised by legal indeterminacy, by the increased efficiency of enforcement, and by the constitutional need to preserve space for discretion, mitigation, and individual circumstance where the law requires them. The OLRF does not dissolve these tensions. It gives them institutional form through the Decision Tree, the Registry, the Coverage Map, the Discretion Point architecture, and the three-model framework, so that they become visible, governable, and reviewable rather than hidden inside implementation practice.
Against that background, the constitutional argument for the OLRF is both conservative and ambitious. It is conservative because it does not ask the legal order to invent new principles for the age of software. It asks that longstanding principles of the Rechtsstaat remain effective when public power is exercised through executable norms. It is ambitious because this requires more than better administrative IT. It requires an architecture in which the core constitutional demands of legality are translated into operational form. Four such demands are central. The system must secure equal treatment. It must make reasons available in a legally meaningful form. It must preserve the public and democratically attributable character of the operative norm. And it must remain proportionate by protecting the space in which individual circumstance and human judgment continue to matter. The remainder of this chapter examines each in turn, showing how each requirement is met differently across the three models while remaining constitutionally constant in its substance13.
Equal Treatment by Design
Equal treatment is the first constitutional requirement that machine-executable law must satisfy if it is to deserve the name of law at all. The principle is simple to state and difficult to preserve in practice: like cases must be treated alike, and differences in treatment must be justified by the norm itself rather than by accident, opacity, or administrative drift. In the German constitutional order this principle is anchored in Article 3 of the German Basic Law. In European law it is reflected in Article 20 of the Charter. In administrative practice across democratic systems it appears in a more concrete form as the requirement that comparable cases not be decided differently merely because they were handled by different officials, different offices, or different technical systems14.
Automated systems seem, at first glance, to promise exactly this. A deterministic system does not tire, does not forget, and does not vary its outcome from case to case for reasons of temperament, workload, or institutional habit. That is a genuine advantage. But it is not the whole story. A system may be perfectly consistent and still be consistently wrong. If the executable specification through which it applies the law reflects an overbroad condition, an omitted exception, an unresolved ambiguity treated as settled, or a contested interpretation silently hardened into code, then the system will reproduce that error with exemplary discipline and at enormous scale. The constitutional problem is therefore not inconsistency alone. It is the combination of consistency with invisibility.
This is precisely where the earlier discussion of legal indeterminacy matters. The OLRF does not rest on the fiction that law can be rendered mechanically complete in every respect. It begins from the opposite insight: that some parts of the law can be specified deterministically, while others remain open-textured, contested, or dependent on human judgment. Equal treatment in this setting cannot mean that everything is automated. It means that everything the system does automate is specified openly, applied identically, and exposed to legal challenge. It also means that the points at which the law does not admit full formalisation are not hidden, but marked as such through Discretion Points and the Coverage Map.
The three models secure equal treatment through different mechanisms. Under Model A, equality is structural: the same Decision Tree, evaluated by the same deterministic engine, produces the same result for the same facts. The guarantee is absolute within the scope of the tree. The risk is that the tree itself may embody an interpretation that treats genuinely different cases alike (because it lacks the granularity to distinguish them) or genuinely similar cases differently (because an exception is modelled incorrectly). Under Model B, equality is validated: the Legal Agent may reach the result through different reasoning paths, but the validation framework ensures that the outcome falls within the corridor that the Decision Tree permits. Deviations are classified and documented. Equality here means not identical reasoning but consistent outcomes within a defined tolerance. Under Model C, equality is audited: autonomous agents may reason differently in different cases, and the retrospective audit assesses whether the population of outcomes is consistent with the norm. Equality here is statistical rather than individual, which is constitutionally weaker. This is the primary reason why Model C requires the most rigorous audit protocol and the highest threshold of agent certification15.
Equal treatment requires not only that the same Decision Tree be applied, but that the agents applying it meet the same certification standards. A norm evaluated by a certified Model B agent and the same norm evaluated by an uncertified system that happens to produce the same output are not constitutionally equivalent. The first determination was produced within the accountability framework that the Rechtsstaat requires: the agent’s competence was assessed, its certification was verified at runtime, and the certification record is part of the Decision Package. The second determination was produced outside that framework: no one assessed the system’s competence, no certification was verified, and the citizen has no institutional basis for trusting the quality of the process. The outcome may be identical. The constitutional quality of the determination is not. This is why the agent certification system (Chapter 10: Agent Certification --- The State Examination for Machine Actors) is part of the equal treatment architecture, not merely a technical quality assurance measure.
Under the OLRF, equal treatment is therefore secured in a more demanding sense than mere algorithmic consistency. A Decision Tree is published in the Registry, linked at sub-normative level to the text from which it derives, versioned over time, and evaluated under defined execution semantics. The question whether the system applied the same rule to comparable cases is no longer answerable only by reference to vendor assertions or internal system documentation. It becomes answerable through a public legal artefact. Courts can examine the Decision Tree. Citizens can contest the legal anchors on which it relies. Auditors can determine whether different outcomes arose from different facts, from different applicable versions, from a deviation classified under Model B, or from an error in the specification itself. Equal treatment is thus relocated from the opaque internals of a software system into a domain of public legal accountability.
That does not eliminate the possibility of error. It changes the constitutional character of error. A hidden implementation defect becomes a visible and reviewable problem of legal specification. A private discrepancy between systems becomes a publicly contestable difference between norm, implementation, and application. The OLRF does not promise infallibility. It promises that equality before the law is no longer left to the goodwill of individual implementations. It is made a property of the architecture, subject to the same forms of scrutiny as the law itself.
The Duty to Give Reasons
If equal treatment protects citizens against arbitrary variation, the duty to give reasons protects them against opaque authority. A state governed by law must not merely decide. It must be able to explain why it decided as it did. That requirement is as old as administrative legality itself. It is reflected in Article 41 of the Charter as part of the right to good administration, embedded in §39 VwVfG as the Begründungspflicht, and indispensable to any meaningful right of challenge. A person who does not know why a decision was made against them cannot assess whether the decision was lawful, cannot identify the relevant point of contestation, and cannot mount an effective appeal §39 VwVfG (Begründung des Verwaltungsaktes); Art. 41 Abs. 2 lit. c EU-Grundrechtecharta (right to good administration, including the obligation to give reasons); CJEU C-222/86, Heylens, 1987, para. 15 (effective judicial protection requires sufficient reasons to enable judicial review)16.
In the analogue world, this duty was fulfilled through the written administrative act. The official was expected to set out the legal basis, the decisive facts, and the reasoning that connected one to the other. The quality of that practice was uneven, but the structure was recognisable. The citizen encountered not only an outcome but a justification. The move to automation puts this requirement under unusual strain. Automated systems are very good at producing outcomes. They do not, by default, produce reasons in a form that law can recognise. An output is not yet an explanation. Still less is it a legally sufficient statement of reasons.
The OLRF responds to this not by treating explainability as an optional compliance layer, but by making it intrinsic to the decision itself. The form of that intrinsic explainability varies across the three models, but the constitutional requirement is constant: the affected person must receive reasons that are specific to their case, traceable to the applicable norm, and sufficient to enable a meaningful legal challenge.
The deficit that the OLRF addresses is not hypothetical. Where the normative basis of an automated decision resides in proprietary code that neither the affected citizen nor the reviewing court can inspect, the constitutional duty to give reasons is structurally unfulfillable, regardless of the administering authority’s good intentions17
Under Model A, every evaluation produces a Decision Package that records the path by which the result was reached: the facts relied upon, the conditions evaluated, the exceptions considered, the parameters applied, the legal anchors activated, and where relevant the point at which human judgment entered the process. The reasoning is produced as a first-class output of the lawful evaluation itself, not reconstructed after the event from logs, heuristics, or model summaries.
Under Model B, the Decision Package is enriched by the deviation record. Where the Legal Agent’s subsumption diverged from the path the Decision Tree would have predicted, the deviation is classified (outcome deviation, reasoning path deviation, fact classification deviation, scope deviation, or structural deviation, as described in Chapter 5), and the agent’s reasoning for the deviation is documented alongside the validation framework’s assessment. The citizen receives not only the outcome and its legal basis, but also an account of how the agent’s reasoning related to the tree’s expected path and why the deviation was or was not within permissible bounds18.
Under Model C, the duty to give reasons takes its most demanding form. The autonomous agent’s reasoning chain is preserved in full, and the retrospective audit’s assessment is included in the Decision Package. The citizen receives the agent’s reasoning, the audit protocol’s evaluation of that reasoning, and the identification of any points at which the agent’s reasoning departed from what the audit protocol considers the correct application of the norm. This is constitutionally more demanding than Models A or B because the reasoning is not generated by a deterministic engine but by a probabilistic system, and the reasons must therefore include not only what the system concluded but how confident the audit protocol is that the conclusion is legally correct19.
This is constitutionally significant for a deeper reason. The duty to give reasons is not satisfied by a general description of how a system usually works. It must be satisfied in relation to this person, this case, this version of the norm, and this reasoning path. That is exactly what the Decision Package makes possible across all three models. The explanation delivered to the affected person is derived from the actual evaluation record, not from an abstract system manual or from post hoc rationalisation. The citizen is told not merely which provision applied, but why it applied here, which condition failed or succeeded, whether an exception was considered, and where discretion, if any, entered the decision.
This is also where the broader architecture of sub-normative linkage becomes essential. Reasons become legally meaningful only when they remain traceable to the enacted text. A statement that a claim was refused because “the system found the applicant ineligible” is administratively useless. A statement that the claim was refused because a specified statutory condition was not met, on the basis of identified facts and under an identified version of the Decision Tree, is a legal reason. The difference is not rhetorical. It is the difference between a citizen being confronted with an opaque output and a citizen being addressed by law.
The OLRF therefore transforms the duty to give reasons from an aspirational quality standard into a structural property of automated administration. Reasons are no longer something that may or may not be added later by an overstretched authority. They are generated as part of the lawful production of the decision itself. In that respect, machine-executable law does not weaken the right to reasons. Properly designed, it fulfils it more reliably than most administrative systems have ever managed to do.
Public Promulgation, Democratic Authorship, and the Dual Publication Model
This is one of the oldest insights of the rule of law and one of Fuller’s clearest requirements. Law must be public. It must be knowable. Its operative content cannot be buried in inaccessible administrative habits, proprietary software, or undocumented internal translations. The difficulty in the digital age is that publication of statutory text alone is no longer sufficient. Where decisions are mediated by executable logic, the question is no longer only what the law says. It is also how that law has been specified for execution. If that second layer remains private, the requirement of public promulgation is only formally satisfied. In practical terms, the citizen is still governed by rules they cannot inspect.
This is the constitutional significance of the dual publication model. The statutory text remains the primary legal source. Nothing in the OLRF displaces that. But alongside the human-readable norm there must also exist a publicly accessible, institutionally attributable, machine-executable specification of how the norm is to operate where automation is used. That specification is the Decision Tree. Its publication in the Registry ensures that the operative form of the law is no longer hidden inside private systems. It becomes part of the publicly inspectable legal environment.
The promulgation requirement extends beyond the Decision Tree itself under Models B and C. Under Model B, the validation framework against which the Legal Agent’s reasoning is checked must also be publicly available. A citizen who is told that their case was decided by a Legal Agent whose reasoning was validated against a framework they cannot inspect faces the same opacity that the dual publication model was designed to prevent. The validation framework is, in constitutional terms, part of the operative normative basis and must be published accordingly. Under Model C, the audit protocol must be published: the criteria against which the autonomous agent’s reasoning is retrospectively assessed. If the audit protocol remains private, the citizen cannot assess whether the retrospective review was rigorous, and the constitutional guarantee of promulgation is defeated20.
The scope of what must be promulgated therefore expands across the three models. Under Model A: the Decision Tree and the Coverage Map. Under Model B: the Decision Tree, the Coverage Map, the validation framework, and the deviation classification criteria. Under Model C: the Decision Tree (as audit protocol), the Coverage Map, the audit assessment criteria, and the agent certification requirements. This escalating promulgation requirement is the constitutional price of increasing AI autonomy. The more the system delegates normative reasoning to agents, the more of the normative infrastructure must be made public to preserve the citizen’s ability to understand, challenge, and contest the basis on which they are governed.
This matters not only because publicity is a value in itself, but because democratic authorship must remain visible when law is translated into executable form. Binding rules must be attributable to a legitimate source of authority. In the context of machine-executable law, that means the executable specification cannot appear as an accidental by-product of software development. It must be tied, institutionally and legally, to the authority entitled to give it force.
For this reason, the OLRF distinguishes between interpretive and authoritative publication. In interpretive mode, the responsible authority publishes the Decision Tree as the formal account of how it understands and will apply the norm. Courts remain fully free to review that interpretation. But the authority can no longer hide behind a private implementation that differs silently from what it has publicly declared. In authoritative mode, the executable specification is itself incorporated into the legal instrument or issued under delegated rulemaking authority. In that case, the machine-executable form no longer merely accompanies the law. It becomes part of the legal act through which the law is made operational.
This is also where the German doctrine of Wesentlichkeit21 enters the picture. The more the executable specification determines matters essential to the exercise of public power or the enjoyment of rights, the less plausible it becomes to treat that specification as a mere technical detail. At that point, what is at stake is not software implementation but the concretisation of legislative choice. The dual publication model answers this by forcing the relevant specification into the open. The legislature, the courts, and the public can see not only the statutory text, but also the operative specification through which that text is applied in practice. Democratic authorship is therefore not dissolved at the moment of execution. It is carried forward into the executable layer in a form that remains public, attributable, and reviewable.
Seen in this light, the dual publication model is not simply an implementation convenience. It is the constitutional answer to a very old problem in a new technical setting: how to ensure that the rules that govern people are genuinely public, traceable to legitimate authority, and not replaced in practice by privately authored surrogates. What the Official Journal and the Bundesgesetzblatt have long been for human-readable law, the Registry and the Decision Tree become for machine-executable law. They make the operative norm visible before it is applied, not merely reconstructable after harm has occurred.
Proportionality, Discretion, and the Preservation of Individual Circumstance
No account of the rule of law in automated administration is complete without proportionality22. Equal treatment and reason-giving are essential, but they are not enough. A system may apply the same rule to everyone and explain itself perfectly, and still produce outcomes that are constitutionally unacceptable because it has no adequate space for the particular case. Proportionality is the principle that prevents legality from collapsing into rigid enforcement. It requires that public power remain responsive to the concrete circumstances of those on whom it bears.
This is where the earlier discussion of open texture and efficient enforcement becomes decisive. Law often uses categories that cannot be exhausted in advance, and democratic societies have long relied on forms of judgment, mitigation, and structured mercy that are difficult to capture in rigid executable logic. The OLRF does not deny this. It takes it as one of its constitutional premises. A system that automated every formally expressible element of a norm while ignoring the places where the norm depends on balancing, evaluation, or human judgment would not be a triumph of legal certainty. It would be a distortion of the law in the name of technical neatness.
The architectural expression of this insight is the Discretion Point. Where the norm calls for the exercise of judgment rather than deterministic evaluation, the system must stop. It must not proceed as though the remaining step were simply another rule to be computed. It must escalate the matter to the human authority entrusted with making that assessment. In this respect, the Discretion Point is not an admission that the architecture has reached its limit. It is the architecture acknowledging where the law itself has placed a limit on automation.
The Coverage Map performs a second and equally important function. It forces the responsible authority to make visible which parts of a norm are implemented, which remain discretionary, which are excluded from automation, and which remain contested. That visibility matters because proportionality in automated governance is not only about what the system does. It is also about what the system declines to do. An excluded element may reflect the judgment that automation would be too coarse for the legal interest at stake. A discretionary element may mark precisely the place where individual circumstance must remain decisive. A contested element may show that the legal order has not yet settled the meaning strongly enough for deterministic specification. In each case, the architecture does not erase constitutional difficulty. It documents it.
The three-model framework adds a further layer to the proportionality analysis. The assignment of a normative domain to Model A, B, or C is itself a proportionality decision, and the Coverage Map must document it as such. A norm that affects fundamental rights (access to social welfare, deprivation of liberty, family reunification) may require Model B or C precisely because the constitutional weight of the decision demands more contextual sensitivity than Model A can provide. Conversely, a norm that involves purely mechanical calculation (tax liability based on declared income and statutory rates) may require Model A precisely because the constitutional demand for equal treatment outweighs any benefit of contextual flexibility. The model assignment is not a technical optimisation. It is a normative choice about the balance between consistency and responsiveness that the constitutional order requires for a given type of decision. The Wesentlichkeitstheorie applies here with full force: the more essential the affected right, the more the decision about the appropriate model becomes a matter for the legislature rather than the implementing authority23.
This also answers, in part, the concern raised earlier about efficient enforcement. A more capable system will tend, all else equal, to enforce more comprehensively and more consistently than human administration has often done. In many respects that is a constitutional gain. But law is not always meant to operate with maximal rigidity. A Coverage Map that classifies every relevant element as fully implemented under Model A and leaves no room for discretion, exclusion, or contestation is not a neutral technical artefact. It is a normative and political choice about how harshly and how uniformly the rule is to be applied. The virtue of the OLRF is not that it makes this choice disappear. It is that it makes the choice explicit and therefore available for democratic scrutiny.
Proportionality, under the OLRF, is therefore not secured by asking the machine to become humane. It is secured by ensuring that the architecture preserves the legal spaces in which humane judgment is required, and by making visible the points at which a public authority has chosen more or less automation, more or less rigidity, more or less room for the atypical case. In that sense, proportionality becomes not an after-the-fact moral gloss on technical infrastructure, but one of the principles that determine its design from the beginning.
Conclusion
Taken together, these four requirements show what the rule of law demands once public power is exercised through executable norms. Like cases must be treated alike, but through mechanisms that vary with the degree of AI autonomy: structural identity in Model A, validated consistency in Model B, audited coherence in Model C. Decisions must be reasoned, but in forms that match the model: deterministic evaluation paths, annotated deviation records, or preserved reasoning chains with retrospective audit assessments. The operative form of the law must be public and democratically attributable, with the scope of promulgation expanding as AI autonomy increases. And automation must remain proportionate to the legal interests at stake, with the model assignment itself subject to the Wesentlichkeitstheorie and to democratic oversight through the Coverage Map.
This is the deeper constitutional claim of the OLRF. It does not ask the legal order to adapt itself to the logic of software. It asks (agentic) software to submit to the logic of the legal order. That is why the framework matters. It does not merely make automated governance more efficient. It makes it more legible, more contestable, and more capable of remaining a form of government under law, regardless of whether the machine that exercises public power operates under deterministic evaluation, guided subsumption, or autonomous legal reasoning.
Footnotes
-
Lon Fuller, The Morality of Law, Yale University Press 1964, S. 33—94 ↩
-
The principle that constitutional requirements are constant across technical implementation forms while the mechanisms through which they are fulfilled vary is established in BVerfGE 120, 274 (Online-Durchsuchung, 2008), in which the Court held that fundamental rights protection must adapt to new technological modalities without the substance of the protection being diminished. ↩
-
Berman, D. H. and Hafner, C. D., “Obstacles to the Development of Logic-Based Models of Legal Reasoning”, in C. Walter (ed.), Computer Power and Legal Language, Quorum Books 1988, pp. 185—214. ↩
-
Sergot, M. J. et al., “The British Nationality Act as a Logic Program”, Communications of the ACM, Vol. 29, No. 5, 1986, pp. 370—386. ↩
-
Bench-Capon, T. J. M. and Sergot, M. J., “Towards a Rule-Based Representation of Open Texture in Law”, in C. Walter (ed.), Computer Power and Legal Language, Quorum Books 1988. The concept of open texture originates in Waismann, F., “Verifiability”, Proceedings of the Aristotelian Society, Supplementary Volume 19, 1945, pp. 119—150, and was applied to law by Hart, H. L. A., The Concept of Law, Oxford University Press 1961, Chapter VII. ↩
-
Branting, L. K., “Data-Centric and Logic-Based Models for Automated Legal Problem Solving”, Artificial Intelligence and Law, Vol. 25, No. 1, 2017, pp. 5—27. ↩
-
The proposition that the machine-executable specification of a statute is not the law itself but a derived, contestable interpretation, published alongside the text and traceably linked to it, has a direct precursor in the Rulemapping method developed by Breidenbach since 2007 in collaboration with the Centre for Legislation and Digitalisation (ZGDigital) and the German Federal Ministry of Justice (BMJ). Breidenbach argues that the path from policy impulse to digitally viable norm must proceed through the visualisation of decision logic: clarifying objectives and options, visualising the decision logic as a structured rule set, deriving the text from the structure, and publishing the norm in machine-readable form for testing and iterative improvement. The Rulemapping method makes the subsumption structure visible and therefore reviewable, which corresponds both to the OLRF’s sub-normative linkage architecture and to the Coverage Map concept: the interpretive decision of how a statute is translated into executable logic is disclosed and thereby open to challenge. See: Breidenbach, S., Was Gesetze sein könnten: Mit Methode zum guten Gesetz, C. H. Beck, Munich 2025 (ISBN 978-3-406-79088-1). For the earlier collaboration with the BMJ and the application to the reform of pension equalisation (Versorgungsausgleich) since 2009: Breidenbach, S. and Rath, C., “Digitalisierung der Gesetzgebung und automatisierten Normumsetzung”, ZGDigital/BMJ, ongoing since 2010; see also Rulemapping Group, www.rulemapping.com (SPRIND-funded since 2024). ↩
-
The three-model taxonomy is not the first attempt to differentiate levels of automation in legal reasoning. Parasuraman, R., Sheridan, T. B., and Wickens, C. D., “A Model for Types and Levels of Human Interaction with Automation”, IEEE Transactions on Systems, Man, and Cybernetics, Vol. 30, No. 3, 2000, pp. 286—297, proposed a ten-level taxonomy for human-automation interaction. The OLRF’s three models compress this into three constitutionally relevant categories distinguished by where the normative authority resides: in the tree (A), shared between agent and tree (B), or in the agent subject to retrospective audit (C). ↩
-
For a comprehensive argument that the degree of formalisation of legal norms is itself a normative choice with constitutional implications: Diver, C., “Against Algorithmic Clarity: The Ambiguity of Rules and the Advantages of Standards”, University of Chicago Law Review (forthcoming 2025); Hart, H. L. A., The Concept of Law, Oxford University Press 1961, Chapter VII (the choice between rules and standards as a choice about the distribution of power between legislature and judiciary) ↩
-
This observation has a parallel in the legal theory of interpretation. Gadamer’s hermeneutic circle (Wahrheit und Methode, 1960) holds that understanding a text requires continuous movement between the part and the whole, between the specific provision and the broader statutory purpose. A system that reduces the text to a fixed tree eliminates this movement. A system that requires agents to reason from the text (Models B/C) preserves it. ↩
-
Kleinig, J., “Selective Enforcement and the Rule of Law”, Journal of Social Philosophy, Vol. 29, No. 1, 1998, pp. 117—131. See also: Husak, D., “Is the Criminal Law Important?”, Ohio State Journal of Criminal Law, Vol. 1, 2003, pp. 261 ff. (arguing that selective enforcement is not merely pragmatic but reflects principled judgments about the proper scope of state power). ↩
-
The constitutional significance of the model assignment decision is analogous to the Organisationsermessen (organisational discretion) recognised in German administrative law, under which the responsible authority’s choice of organisational form for the exercise of public power is itself subject to constitutional limits. See: BVerfGE 63, 1 (Schornsteinfeger, 1982); Maurer/Waldhoff, Allgemeines Verwaltungsrecht, 20. Aufl., C. H. Beck 2020, §21 Rn. 50 ff. ↩
-
The ambition of translating constitutional demands into operational form, so that architectural properties of the system enforce what normative requirements alone cannot guarantee, draws on a tradition that spans legal theory, information policy, and regulatory design. The foundational insight is Lessig’s: that technical architecture is a modality of regulation, operating alongside law, markets, and social norms, and that the design of technical systems determines which behaviours are possible, which are default, and which are effectively prohibited, often more reliably than legal prohibition alone (Lessig, L., Code and Other Laws of Cyberspace, Basic Books 1999; revised as Code: Version 2.0, Basic Books 2006). Reidenberg formalised this as “Lex Informatica”: the observation that information policy rules are increasingly embedded in the technical architecture of networks and systems rather than in legal texts (Reidenberg, J., “Lex Informatica: The Formulation of Information Policy Rules Through Technology”, Texas Law Review, Vol. 76, 1998, pp. 553 ff.). Hildebrandt inverts the perspective and turns it into a normative programme: if architecture regulates, then those who design architecture for public institutions have a constitutional obligation to design it in ways that protect rather than erode fundamental rights. She terms this “Legal Protection by Design” (Hildebrandt, M., “Legal Protection by Design: Objections and Refutations”, Legisprudence, Vol. 5, No. 2, 2011, pp. 223 ff.; see also Hildebrandt, M., Smart Technologies and the End(s) of Law, Edward Elgar 2015, Chapters 8 and 9). The OLRF’s claim is that this programme can be made concrete: not as a general aspiration that systems should respect rights, but as a specified architecture in which equal treatment, reason-giving, public promulgation, and proportionality are structural properties of the system rather than aspirational qualities of the humans who operate it. In this sense, the four demands examined in this chapter are not merely constitutional requirements that the OLRF must satisfy. They are design specifications from which the architecture was derived. ↩
-
BVerfGE 1, 14 (Südweststaat) --- zur Gleichheit als Grundprinzip des Verwaltungshandelns; Art. 3 GG; Art. 20 EU-Grundrechtecharta. ↩
-
The distinction between individual equality (each case treated identically), outcome consistency (outcomes within a permitted range), and statistical coherence (the population of outcomes consistent with the norm) maps onto the doctrinal distinction in German administrative law between Gleichbehandlung (equal treatment), Selbstbindung der Verwaltung (administrative self-binding through consistent practice, BVerwGE 34, 278), and Willkürverbot (prohibition of arbitrary deviation, BVerfGE 1, 14). Model A secures the first. Model B secures the second. Model C secures the third. The constitutional adequacy of the weaker forms depends on the weight of the affected right. ↩
-
§39 VwVfG (Begründung des Verwaltungsaktes); Art. 41 Abs. 2 lit. c EU-Grundrechtecharta (right to good administration, including the obligation to give reasons); CJEU C-222/86, Heylens, 1987, para. 15 (effective judicial protection requires sufficient reasons to enable judicial review). ↩
-
Braun Binder, N., “Vollständig automatisierter Erlass eines Verwaltungsaktes und Bekanntgabe über Behördenportale”, DÖV 2016, pp. 891 (895 f.), identifying the problem that fully automated administrative acts under §35a VwVfG raise the question of how courts can fulfil their review function when the normative logic of the decision resides in software code that is neither publicly accessible nor structured in terms that map onto legal reasoning categories. The OLRF’s Decision Package is the architectural response: a signed, structured record that documents the evaluation path (Model A), the deviation record (Model B), or the full reasoning chain with audit assessment (Model C) in a format that courts can inspect without requiring access to the system’s source code. ↩
-
The enriched Decision Package under Model B responds to the concern raised by Wachter, S., Mittelstadt, B., and Floridi, L., “Why a Right to Explanation of Automated Decision-Making Does Not Exist in the General Data Protection Regulation”, International Data Privacy Law, Vol. 7, No. 2, 2017, pp. 76—99, that existing legal frameworks require explanation of the logic involved, not merely the outcome produced. The deviation record makes the logic visible. ↩
-
The requirement that Model C reasoning chains be preserved in full and subjected to retrospective audit is the OLRF’s response to the epistemic asymmetry identified by Burrell, J., “How the Machine ‘Thinks’: Understanding Opacity in Machine Learning Algorithms”, Big Data & Society, Vol. 3, No. 1, 2016: that the opacity of AI reasoning is not merely practical (the system is complex) but fundamental (the reasoning process is not structured in terms that map onto human legal categories). Preserving the full chain and subjecting it to structured audit is the architectural minimum for constitutional compliance. ↩
-
The expanding promulgation requirement across the three models follows the logic of BVerfGE 49, 89 (Kalkar I, 1978): the more significant the decision, the more the normative basis on which it rests must be specified by the legislature and made public. Under Model C, where the audit protocol is the primary constitutional safeguard, its non-publication would be equivalent to a secret law. ↩
-
BVerfGE 40, 237 (Parlamentsvorbehalt/Wesentlichkeitslehre); BVerfGE 49, 89 (Kalkar I). ↩
-
In the European constitutional tradition, proportionality operates at three levels: suitability (the measure must be capable of achieving the legitimate aim), necessity (no less restrictive means must be available), and proportionality stricto sensu (the burden imposed on the individual must not be disproportionate to the public interest served). It is the third level that matters here. A fully automated system may be suitable and necessary for the efficient administration of a norm. But if it eliminates the capacity to recognise the atypical case, the individual whose circumstances fall outside the norm’s anticipated range bears a burden that the legislative purpose did not intend to impose. The Bundesverfassungsgericht has articulated this as a constitutional requirement of Einzelfallgerechtigkeit (justice in the individual case): the administrative application of general rules must remain capable of accommodating the particular circumstances of the person affected, even where this creates friction with the demand for consistency. See: BVerfGE 75, 108 (118 f., Künstlersozialversicherung, 1987); BVerfGE 99, 216 (233, Familienlastenausgleich, 1998), holding that the legislature must design benefit systems in ways that do not systematically exclude atypical household structures from adequate provision. Alexy’s weight formula provides the theoretical framework: proportionality stricto sensu requires that the degree of interference with the affected right be justified by the degree of realisation of the competing public interest, assessed on a case-by-case basis rather than as an aggregate calculation across the population (Alexy, R., A Theory of Constitutional Rights, Oxford University Press 2002, pp. 100 ff.; Alexy, R., “On Balancing and Subsumption: A Structural Comparison”, Ratio Juris, Vol. 16, No. 4, 2003, pp. 433 ff.). The OLRF’s Discretion Point architecture is the operational translation of this requirement: it identifies the points at which the weight formula cannot be resolved by general specification and must be applied to the concrete circumstances of the individual case. The Coverage Map documents the scope of this reservation, making visible where the responsible authority has judged that automation must yield to individual assessment. ↩
-
The application of the Wesentlichkeitstheorie to the model assignment decision is, to our knowledge, a novel doctrinal proposition. Its logic follows from the Court’s own reasoning: if the procedural form of a decision must be proportionate to its constitutional weight (BVerfGE 49, 89, 126 f.), and if the choice between Models A, B, and C determines the procedural form of automated decision-making, then the model assignment is itself a Wesentlichkeits-relevant decision. For decisions affecting fundamental rights, it must be made by the legislature or under sufficiently specific legislative delegation, not left to the implementing authority’s technical discretion. See also: Martini, M. and Nink, D., “Wenn Maschinen entscheiden… Vollautomatisierte Verwaltungsverfahren und der Persönlichkeitsschutz”, NVwZ-Extra 10/2017, pp. 1—14, arguing that §35a VwVfG imposes constitutional limits on the scope of automated decision-making that parallel the Wesentlichkeitstheorie. ↩